Why File-Based AI Memory Will Power Next-Generation AI Applications
Remember when businesses used to rely on clunky hardware, SQL queries that took eight hours to run on Microsoft SQL Server, and visualization tools that had been bought out and discontinued so long ago that the most recent help forum posts were already years old?
To me, those days still feel close—especially when I recall the summer of 2016, the entirety of which I spent fixing long queries and learning the ropes of the business. But that all changed when cloud computing took over and quietly started revolutionizing the way companies stored and managed their data.
It took a few years for mass adoption of the new paradigm, but the end result was a centralized, scalable, and globally accessible data system. Hardware maintenance and hours long SQL queries faded into the background, and a new era of digital agility took its place.
Just as this migration liberated businesses from the burden of managing physical hardware, we're now on the cusp of another transition to a new foundational technology—one that will define the next generation of intelligent systems. This shift is toward file-based AI memory.
Where the cloud enabled companies to scale their computing and data storage, the implementation of AI memory will empower them to build copilots, intelligent apps, and fully automated, self-optimizing workflows.
These systems will not just serve to store information, but will be able to deeply understand and reason with it, catalyzing the emergence of a vast spectrum of new initiatives and business functions.
Why AI Memory Matters: Bridging the Data Meaning Gap
Today, most organizations are drowning in fragmented data—scattered across data warehouses, spreadsheets, APIs, legacy databases, and a bunch of other silos. Connecting this chaos to LLMs isn’t just about doing some mandatory housekeeping—it's the key to unlocking innovation at scale.
If businesses truly aim to grow to their full potential, they need to bridge the divide between traditional, relational systems and emerging technologies, creating a unified semantic memory layer that makes their data comprehensible and actionable.
This data layer, powered by file-based AI memory, transforms a raw, messy database into a structured, insightful information source. It doesn't just plug into existing systems to simplify storage—it clarifies meaning, context, and relationships between data points, enabling LLMs to reason and intuitively interact with business information.
But integration itself isn't the end goal. The real opportunity lies in using this semantic memory layer for automating the continuous optimization of systems and processes.
As a business evolves, so too do its data requirements. With AI memory, applications become adaptive, capable of dynamically responding to shifting objectives, evolving datasets, and emerging business needs—seamlessly and intelligently.
No more duct tape integrations or wishful prompting; just a structured, scalable data ecosystem designed for meaningful AI-driven innovation.
Emulating Human Memory Using Cognitive Science Principles
A few years ago, I noticed something strange in the IT sector: with all the progress we'd made, we've failed to give enough consideration to how long-standing scientific models of the human mind might inform our approach and enable us to build better tech. I then felt a pull to go back to school, hoping that a degree in psychology might help me better understand the mechanisms that underlie our higher cognitive processes.
One of the things I’ve learned that continues to fascinate me was that the human memory isn’t static; it continuously adapts, reshapes itself, and finds new ways to deal with ambiguity. This made me realize that our approach to AI memory needed to integrate the same kind of flexibility and resilience.
That’s why I believe AI memory must excel at these three things:
- Handling uncertainty: Dealing gracefully with missing or inaccurate data and finding the simplest effective ways to overcome obstacles.
- Evolving with the business needs: A five-person startup and a fifty-person company have radically different memory requirements. The system should know that and auto-optimize towards data representation models that can dynamically handle the problems of the business.
- Responding to crises: Detecting failures, shifting priorities, and deadline crunches—then triggering focused retraining, memory restructuring, or context reprioritization as needed.
To be truly effective, AI infrastructure can’t be rigid and inert—it must be a living, self-advancing system that continuously loads and updates the data, turning it into a semantic layer understandable to the LLM.
From Vertical Apps to Intelligent Agent Networks
In the first blog post I wrote when I was just starting cognee, I had this hunch that future AI systems would resemble human teams—cohorts of agents, each with their own unique context and memory, all working toward shared goals. I called them “Agent Networks.” That idea felt a bit abstract back then.
Now, as more vertical apps enter the market—coding copilots, workflow assistants, website generators—that idea is no longer far-fetched. But if these systems are going to collaborate meaningfully, they need a reliable, structured memory they can all share.
👉 That’s the gap we set out to fill with cognee.
Engineering AI Memory: Access, Reasoning, Veracity
From an engineering standpoint, designing AI memory is about much more than just hooking up a database. It requires three things:
- Access at scale: Agents need high-throughput, low-friction access to all available data—structured, semi-structured, and relational.
- Cognitive flexibility: Like human minds, agents need different types of memory (e.g., episodic, semantic, working) to reason effectively.
- Hallucination control: Output needs to be consistently and reliably grounded in truth— and more formal ontologies
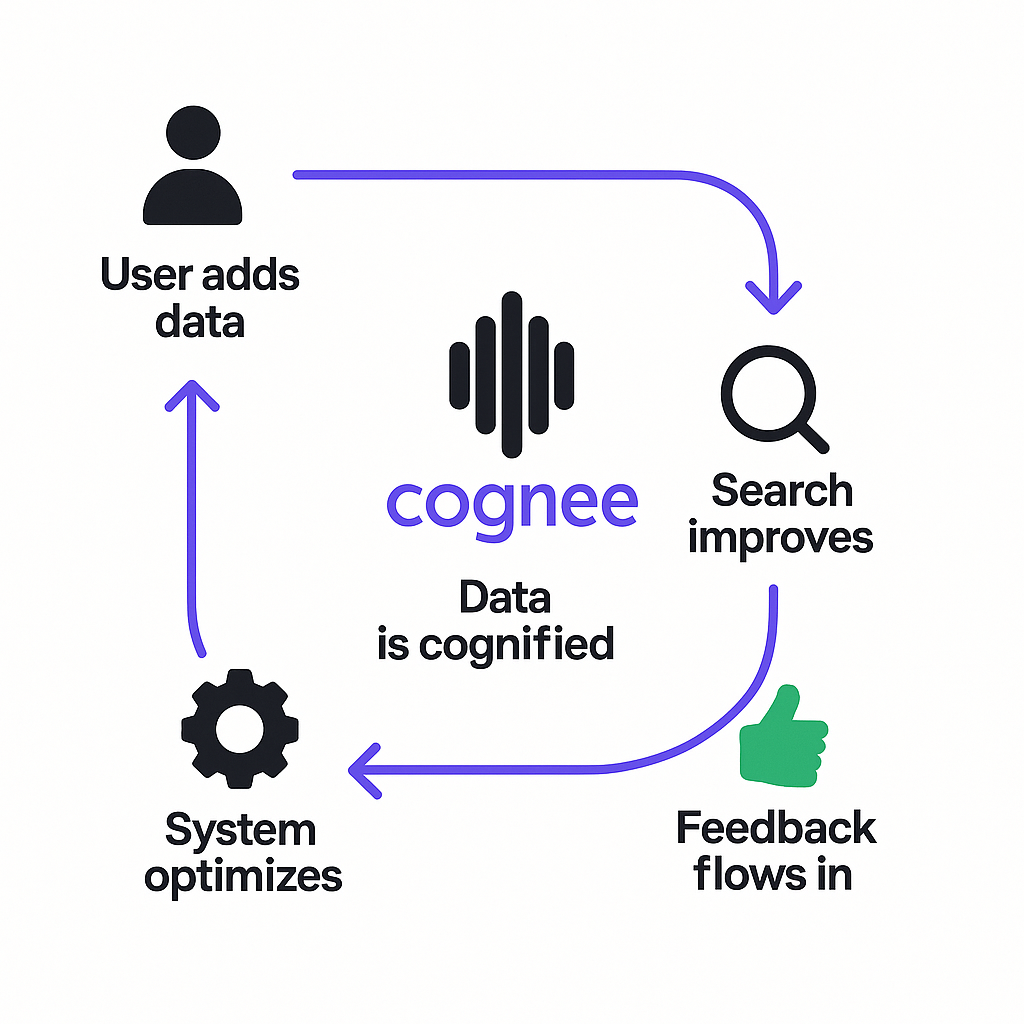
The Two Feedback Loops of Dynamic AI Memory
The memory engine we’re building here at cognee is always learning and evolving. We’ve designed it around two feedback loops:
- Loop One – (Near) Real-Time: As users add data, memory is updated and its processing improves. That loop feeds right back into better search, tighter reasoning, and enhanced retrievals.
- Loop Two – Strategic Optimization: Behind the scenes, the system tunes itself—adjusting ETL parameters, data chunking strategies, and indexing rules to make everything sharper.
The Two Core Systems Behind cognee’s Magic
cognee enables companies to use AI memory via two major, complementary components:
-
Internal System: Our open-source library (plus a growing community lib) lets developers build flexible, modular semantic memory systems quickly and cleanly. It optimizes itself, but only so-much can be done at a runtime.
-
External System – dreamify: Our optimization engine, dreamify, understands the state of a memory pipeline it’s plugged into and adjusts it in for maximum performance and accuracy.
👉 Read in our paper exactly how dreamify works.
These tools work together to provide memory that understands context and adapts over time. We believe that only a dynamic system like this one will be able to support a data layer that will power the AI applications and Agents of the future.
The Future of AI Memory: A Familiar (R)evolution
Still, though, let’s keep it real for a second. I’m not saying that AI-driven memory stores will be some dramatically reinvented infrastructure that will be decoupled from everything else on the market; rather, I assume that it will look more like what we’re working with today—file-based sets of graph embeddings, sitting in some S3 bucket, managed by tools like cognee.
And you know what? That’s fine. It works. It scales. It integrates. This isn’t a revolution that does away with everything that came before—it’s an evolution that plugs directly into it.
We’ve tried what’s out there. We’ve talked to builders. We’ve built, broken, and rebuilt. Now, we’re sharing these tools with you.
If you're building agents, copilots, or any AI app that needs to reason, recall, and evolve—it’s time to turn your data into memory, and your memory into intelligence.
Start scaling today.


