Enabling AI memory to scale with cognee & Iceberg & Tower
Building a lakehouse is fun - until it isn’t. Between object storage, catalogs, engines, and AI tooling, you can quickly end up with a spaghetti bowl of services and credentials. In this post we show how Cognee and Tower let you keep the pasta on the plate: we’ll save some HackerNews articles into an Iceberg table, get it with Polars, feed it into Cognee to build a knowledge graph, search that graph, and then push the AI results back into Iceberg—all without spinning up Spark or Airflow yourself.
TL;DR
- 💾 Store Sample HackerNews articles → Iceberg (Tower SDK + PyArrow)
- 📖 Read Polars pulls them back from Iceberg
- 🧠 Process Cognee converts text → knowledge graph
- 🔍 Search Run natural-language queries on the graph
- 🔁 Loop Persist search results to a second Iceberg table
After setting up your LLM_API_KEY, you can run the whole thing with two commands:
Why Iceberg + Tower + Cognee?
Iceberg as the lingua franca of storage
Apache Iceberg gives us ACID tables on object storage, snapshot time-travel, and engine freedom. It is quickly becoming the one storage “language” that all compute engines are required to speak. By parking our raw text and AI outputs in the same catalog, we dodge the “data copy” tax that hits so many LLM projects.
Tower as the managed Python container
Tower’s managed runtime (quickstart) knows how to create, append, and query Iceberg tables straight from ordinary Python scripts—no separate Spark/Hive stack required. Under the hood, Tower uses an Iceberg catalog (we chose Snowflake’s Open Catalog) and its Tower SDK provides easy access to Iceberg tables via Python APIs. This means our script can talk to Iceberg by name (through tower.tables(...)), and Tower handles the PyIceberg catalog configuration and IAM roles for us after the initial setup.
Cognee as the brain
Cognee turns any kind of data into an RDF-style knowledge graph that you can query with plain English; installation is a single pip install cognee. It’s an open-source AI memory layer that transforms structured or unstructured data into an interconnected knowledge graph with embedded semantic context. You can ask questions through cognee.search(...) and it will combine vector similarity and graph traversal to find relevant answers
Prerequisites
| What we need | Why we need it |
|---|---|
| Snowflake Open Catalog account | Allows easy access to Iceberg tables |
| S3 bucket | Object storage for Iceberg tables |
| Tower | Deploys and runs the demo and optionally schedules it |
| Python 3.11+ and some libraries | Runtime & libs |
For step-by-step setup of the S3 bucket and Snowflake Open Catalog, see Tower’s blog series on building an open lakehouse. Especially Part 4, 5, and 6 walks you through all the necessary steps.
Step 1 – Store 🔄 Iceberg
The script first calls tower.tables("hackernews_stories").create_if_not_exists(...), which under the hood sends a REST call to Snowflake’s Open Catalog and writes Parquet/manifest files to S3 via the IAM role you created earlier. Data conversion is pure PyArrow.
Step 2 – Read 📖 with Polars
Because Tower returns Polars DataFrames out-of-the-box, reading is literally:
Polars now supports Iceberg-native scans through PyIceberg so the DataFrame is backed by Arrow buffers, keeping things fast and memory-efficient.
Step 3 – Build 🧠 the Knowledge Graph
We get stories and add to cognee with cognee.add(), then run cognee.cognify() to materialize nodes & edges. Under the hood Cognee stores everything in its embedded triple-store so later searches are sub-second.
If you peek into tech_articles_content.txt you’ll see exactly what the LLM processed.
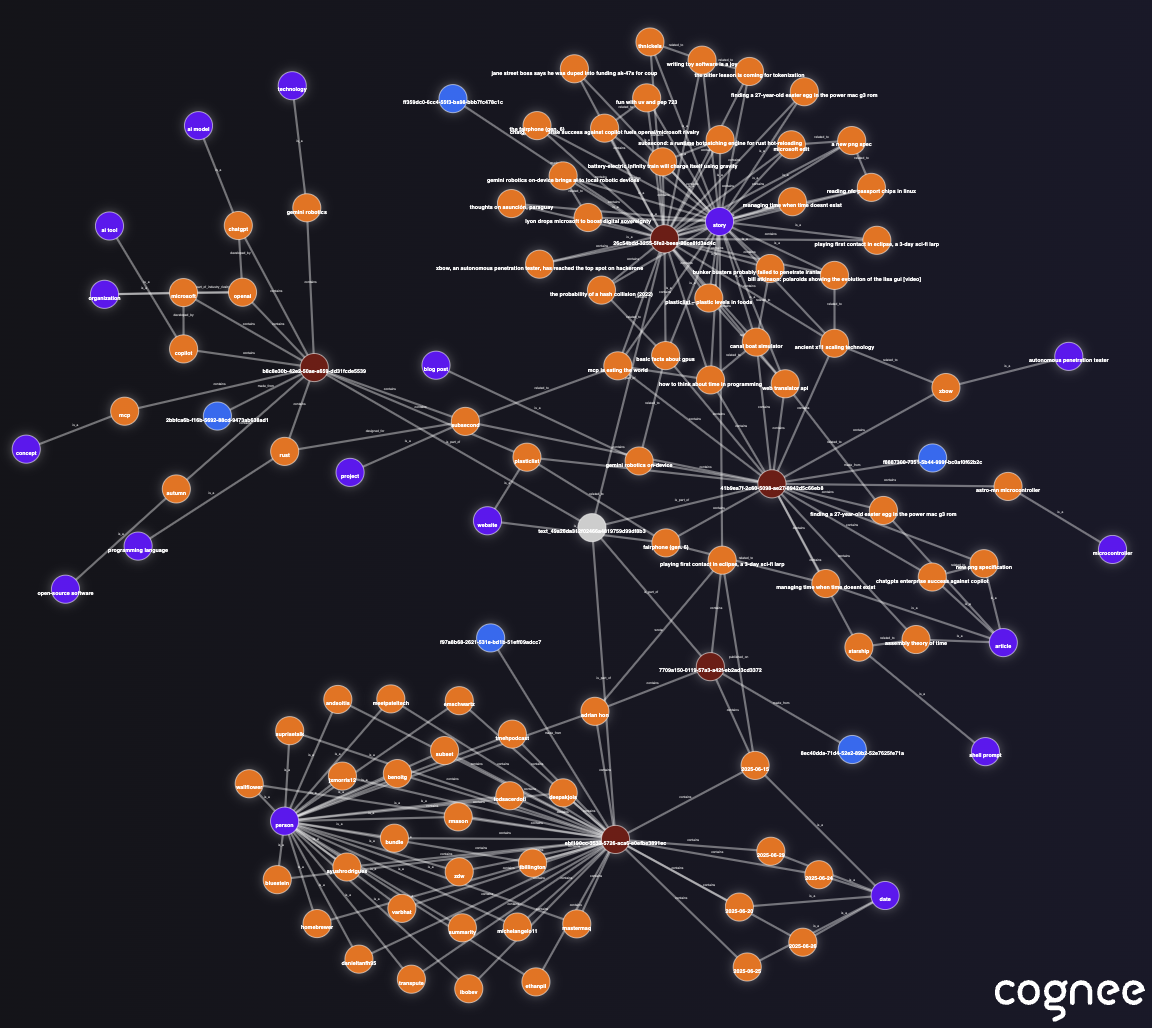
After cognify(), Cognee’s internal knowledge graph contains the entities and relationships extracted from the Hacker News posts. It’s essentially an RDF-like triple store of the content, enriched by the LLM. (If you’re curious, cognee also saved a graph_visualization.html in the local working directory – opening that will show an interactive graph of the nodes and edges.) Here is an example snaphot:
Step 4 – Search 🔍
The demo fires off a single question:
Cognee performs retrieval across graph nodes and prints a nicely formatted answer. (Add more queries to taste.) Here is an example answer for the above query:
"["The main technology topics discussed in the Hacker News stories include:\n\n1. AI and Machine Learning: Focused on developments like ChatGPT and its rivalry with Microsoft's Copilot, as well as Gemini robotics bringing AI to local devices.\n2. Programming and Software Development: Discussions around time management in programming, hot-reloading engines for Rust, and tools for building applications.\n3. Cybersecurity: Highlighting tools like XBOW for penetration testing and Electromagnetic Fault Injection (EMFI).\n4. Hardware and Graphics Processing Units (GPUs): Topics covering GPU basics and intersections with other technologies.\n5. Blockchain and Tokenization: Analyzes the implications of tokenization and related technological lessons."]"
Step 5 – Write 🔁 AI insights back to Iceberg
Finally we copy the search question + answer into a table called cognee_search_results. That round-trip is one table.insert() away, reusing the same IAM role and catalog privileges you set up earlier. The code simply wraps the query and result into a PyArrow table using a predefined schema and inserts it:
Just like that, our LLM-driven insights are persisted in Iceberg next to the original data. We can time-travel or join across these tables using any engine that speaks Iceberg.
Running in Tower Cloud
Want this job to run every 24 hours? You can directly modify it in your Towerfile:
Deploy this job to the Tower cloud and let Tower’s scheduler do its thing:
Tower packages the Python code and its dependencies and ships it to its cloud environment. When it is time, it will start the execution and make metrics and logs accessible in its web UI.
What’s next?
- Cognee S3 File System: In this demo, cognee data stores live in its own file system. We are testing an S3-backed filesystem for cognee, which will allow the pipeline outputs to persist on cloud storage and be accessible easily from external systems. Cognee already supports various graph, vector, and relational databases for scalability - see here – so an S3 integration will let the AI memory help scale beyond.
- Decoupled pipeline apps: In this demo, one script handles everything end-to-end. A next step is to split it into separate Tower apps for ingestion, pipelines (like cognify from this example), and querying, using Tower’s orchestration features. Tower supports one app running others and waiting for completion, so for example we could have an ingest app (fetching new HN stories), which then triggers a Cognee app to update the graph, and finally a reporting app to query and store results. This modular approach would make the workflow more maintainable and allow independent scheduling of each part.
- Build your own apps on Tower with cognee: Cognee and Tower has way more to offer. Experiment with cognee’s tasks and pipelines, use ontology capabilities, build memory for your own use case.
Useful Links to Get Started
If you have any questions, comments or you simply want to connect with other developers, here are some ways to join cognee and tower communities!
Happy lakehousing! 🏖️


