AI Memory in 5 Scenes — From Generic GPT to GraphRAG Greatness
Try telling people at a party that you work in AI memory, and watch their expressions. The typical reaction is a polite “Oh, cool” accompanied by the silent turning of internal gears of confusion. Casual AI users often say something along the lines of “ChatGPT can already remember the start of the chat—so what exactly is there to work on anymore?” Meanwhile, people in the field usually go for snarky retorts such as “So… embeddings and RAG, huh? How’s that working out for you?”
This happens to all of us working here at cognee. Turns out, even for seasoned devs, “AI memory” can mean a lot of things and the lines between them can get blurry fast. So, we thought we’d give our readers an unusual tour of the concept in five hypothetical scenarios set in five different life stages and situations. Through these stories, we’ll be analyzing AI memory through the practical prism of its framework progression: from base LLM to classic RAG to advanced, graph-aware RAG.
To keep the topic focused, we’ll be covering only knowledge-graph-based, GraphRAG-style systems, and leave agentic/long-horizon discussions for another day.
Confused already? Let’s dial it down a notch and start from Scene 1.
Scene 1: A Kid in a Library
Picture yourself as a 12-year-old in a library. Yes, a real library with real books that have that real old book smell. You need help finding a book that will help you learn about dinosaurs for your specific school project. And in this library, there are three employees available.
First, the New Young Employee. He’s well-read for sure, and he can talk confidently about dinosaurs if you ask him—but he doesn’t know zilch about this specific library. Ask him where the dinosaur books are, and he'll just blink. Plenty of knowledge; no sense of place.
Next, you meet the Employee Staring at a Screen. He can type in any book title and find exactly where it is, then read you its synopsis. Is it accurate? Yes. Useful? Kinda. Does he know if the book is any good, or whether it can help you with your assignment? Not a clue. He's all search, no meaning.
Finally, there's the Senior Librarian. She is the library. She doesn't just find books; she lives and breathes them and knows how they all connect. She remembers some old history book that has exactly the dinosaur chapter you need for your school project. She doesn't just give you facts; she understands how everything fits together.
These three employees are like the three types of AI you can use today. You've probably used ChatGPT, which is a type of AI called a Large Language Model, or LLM for short. The New Young Employee is just like a base LLM—broad, articulate, but unaware of your specific needs.
The catalogue reader is basic RAG: good at finding and quoting facts without deeper structure. And the Senior Librarian is graph-aware retrieval: it knows how pieces relate, so it can genuinely help you solve the task, not just hand you text. We'll explore how these two work in the next levels.

Scene 2: A High Schooler at the Movies
You're trying to pick a movie on a streaming service—you want to watch a great animated film and you've got three AI options.
First up: ChatGPT. It suggests Spirited Away or Toy Story. Excellent choices for sure—but it has no idea what’s actually available on the platform you have a subscription for. That’s a base LLM: generally smart but disconnected from your reality.
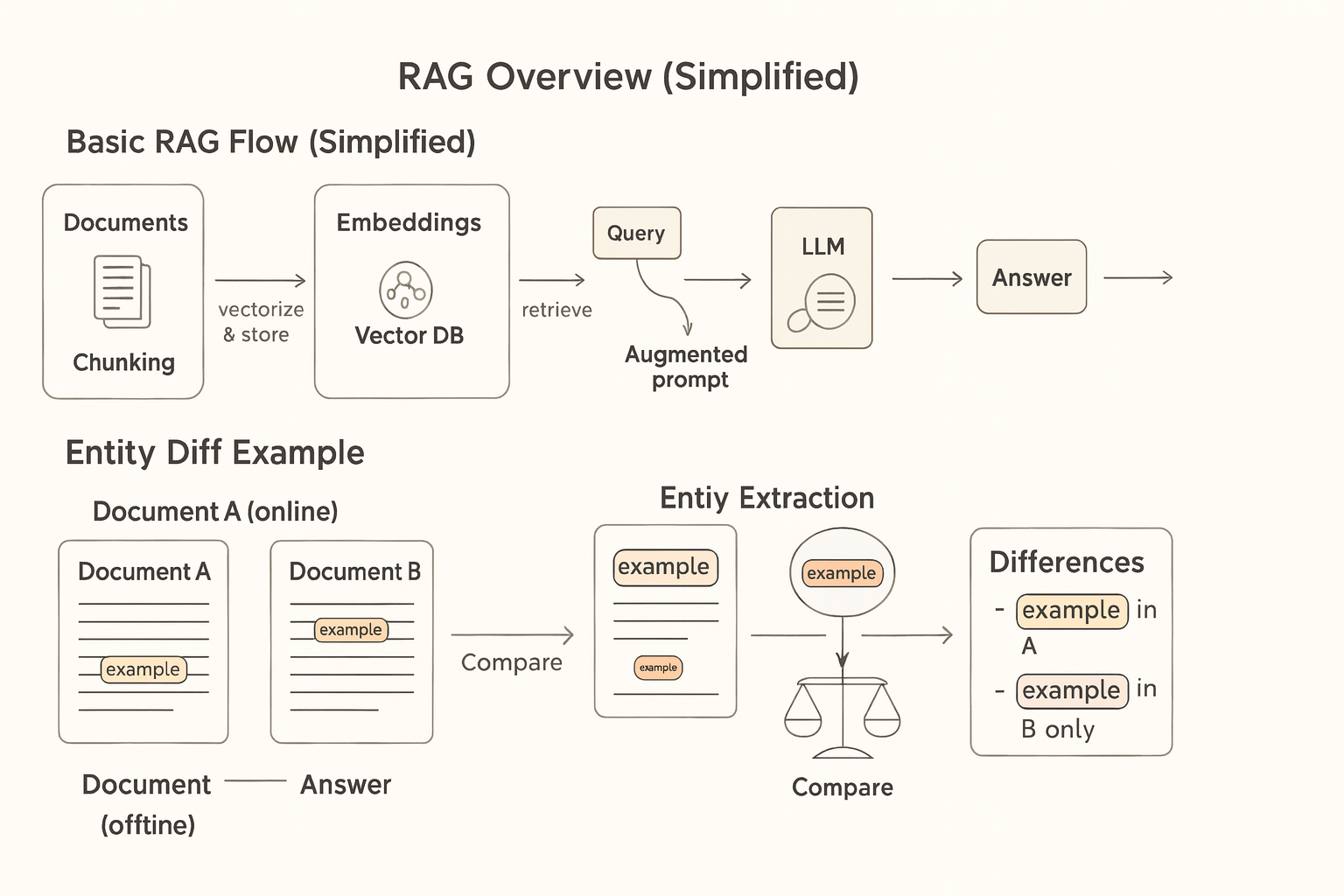
Next option: the Platform's Free Bot. It searches the platform’s database and retrieves the top results. Then it shovels a big blob of summaries, casts, and reviews into the LLM alongside your question. This combined text is the context the model sees. Better than nothing—there’s real data in there—but it’s noisy, redundant, and indifferent to what you actually care about.
Third option: the Personal Movie Guru. This AI gets you. It searches the same catalogue, but instead of dumping raw text, it constructs a cleaner context based on what it knows about you: “User prefers Pixar + adventure. Up matches both; Coco is similar in tone; both are available on their plan.” It might call the LLM a few times to refine that scaffold. The result? Structured, preference-aware, and grounded in availability.
Scene 3: A College Student Preparing for an Exam
You've got an exam coming up and you want to use AI to help you study. You have all your lecture notes, slide decks, and scanned chapters scattered across folders on your laptop.
If you ask ChatGPT what Professor Miller said about entropy—it will provide a decent definition of the concept, but nothing from your actual course. You could pass it the documents one by one, but it’s tedious and the model can't hold all of it in its memory anyway.
But there are tools that can actually help. These tools start by breaking your notes into small chunks. Each chunk gets converted into a number sequence that captures the meaning of the text—a vector embedding.
Your question about Prof. Miller’s comments on entropy gets vectorized too, and the system will find the most similar chunks via semantic search. Those chunks then get appended to your prompt and sent to the LLM.
That’s Retrieval-Augmented Generation (RAG) in action. For direct, factual questions like yours, it can work quite well: it’s quick, relevant, accurate.
But an understandable follow-up like “Which examples did the professor use for entropy that weren’t in the textbook?” would require cross-document reasoning with a negative filter applied. Standard RAG would struggle here because similarity search alone doesn’t capture relationships such as “lecture example” vs “textbook example,” nor does it track references across different sources.
What more advanced systems do is start to name things in your material—‘example’, ‘theory’, ‘formula’—and connect them: lecture → mentions → example; textbook → contains → example. They still keep text chunks, but also store the entities and their relationships. Now we’re approaching a knowledge map that understands how ideas relate, not just which paragraphs look alike. Hold that thought for Scene 4.
Scene 4: A Junior IT Engineer on a Job Hunt
You're job hunting and want to narrow the selection down, ideally to remote-first positions in Series B startups with 20-50 employees that use Python and React and are not in the fintech industry.
Ask ChatGPT-with-web and you’ll get a generic list—plausible names, weak verification, and little acknowledgment of your constraints.
Then you scrape job posts across different platforms and pipe them into RAG. This is better than nothing—it surfaces roles that mention your keywords. But it still struggles to enforce the full set of filters. “Startup culture” sneaks in for later-stage companies; “remote” appears in “hybrid role: 50/50 in-office and remote”; an otherwise perfect position turns out to be in fintech.
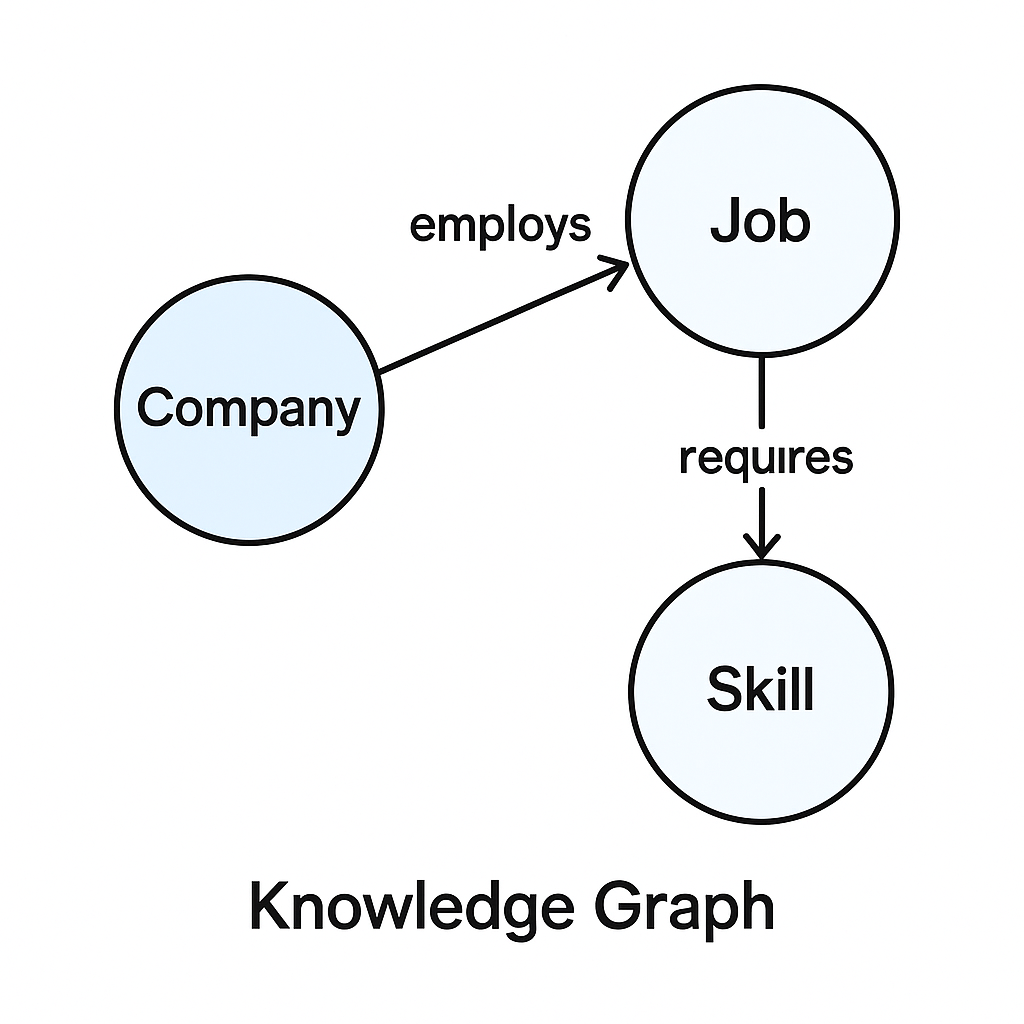
Here's what you could do instead: use LLM calls to extract entities—like Company, Job, Skill, FundingStage, Industry, LocationPolicy, TeamSize—and relations such as employs, requires, operates_in, is_stage, has_size. Store these as a knowledge graph linked back to evidence passages. Now retrieval isn’t “give me similar text,” it’s “give me the subgraph that satisfies (Stage = Series B) ∧ (TeamSize ∈ [20,50]) ∧ (Skills ⊇ {Python, React}) ∧ (Industry ≠ Fintech) ∧ (RemoteFirst = true), plus citations.” This is GraphRAG: hybrid search over entities/relations and supporting snippets.
You can embed entities and edges to keep semantic similarity in play, then use graph filters to honor constraints precisely. The result feels like that senior librarian again—structured meaning first, with the receipts attached.
Scene 5: An AI Startup CTO at a Party
You're back at that party. One person nodded and continued the conversation: a seasoned fellow professional, someone who shares your passion for deep tech discussions and has enough stories to fill a book. You geek out about the evolution of AI from clunky, rule-based systems to RAG models that impressed in theory but faltered in practice.
You both agree the consensus among people who actually build this stuff is clear: the only path forward is a hybrid memory architecture, grounding semantic search in the structured logic of a knowledge graph. And in the real world, there's the classic challenge of balancing speed, quality, and measurability.
Speed. Hybrid retrieval sounds elegant until you’re chasing sub-second responses while combining vector similarity, inverted indices, and subgraph filters. You can have the most sophisticated retrieval logic in the world, but if it takes thirty seconds to return results, users will abandon ship. The fixes are workmanlike: pre-compute hot subgraphs; cache aggressively at retrieval and answer layers; route queries (RAG vs GraphRAG) with a lightweight classifier; degrade gracefully (coarse → fine retrieval) when time budgets are tight.
Quality. Results depend on meaningful entity types and schemas, which often require custom ontologies. But curating ontologies manually isn’t scalable and automatic ontology generation sounds great until you realize how domain-specific the relationships need to be. So you iterate: start with a minimal vocabulary of entities/edges; attach temporal attributes (valid-from/to) as facts change, add event-based knowledge graphs, and, suddenly, you find yourself dealing with versioning thousands of entities and their evolving relationships without breaking existing queries.
Measurability. Precision/recall aren’t enough anymore. You need suites that track retrieval quality (coverage, redundancy, leakage), answer faithfulness (groundedness, citation accuracy), and operational SLOs (latency, throughput, cost/answer). LLM-assisted benchmarking is relatively useful—when paired with stable “golden” sets and human spot-checks. Without rigorous evaluation frameworks and transparent overview of your system's behavior, you're building with sand instead of concrete.
There's a reverberating pause in the conversation—not an awkward one, just one of mutual recognition. The challenges are real, but so is the upside. The next wave of AI systems will wrestle with deep, multi-constraint problems that span many specialized domains.
And, if you work at cognee, it’s hard not to be proud of working toward exactly that future.

What’s Next for AI Memory
We’ve walked the floor from the confused kid in the library to the veteran IT CTO; from basic LLMs to AI memory systems in production. You've seen why simple RAG isn't enough, and where and how knowledge graphs help. You've read about what’s under the hood and about the real-world challenges.
The field is moving fast, and it's exciting to be part of it. There's still so much to explore: new ideas and concepts breaking into industries, the intricate and rich connection between AI memory and agentic systems, the evolution of evaluation frameworks… We’re in it all for the long haul.
Join our Discord to continue the conversation! And, if you enjoyed this five-levels-of-complexity format, feel free to suggest topics for future posts!


