Connecting the Dots: How cognee Links Concepts & Documents with a Graph-Based Approach
When you work with large volumes of unstructured text—tens of thousands, or even millions of documents—it’s easy to end up with a sea of disconnected information. Traditional retrieval approaches can find the “closest” text snippets, but they lack any real understanding of how concepts relate.
That’s why we’re building cognee with a graph-native retrieval engine. Instead of treating documents like isolated islands, cognee maps them into a connected network of ideas, entities, and topics—so your AI can reason about how information is related.
Recently, Laszlo from our team created a short video showing exactly how this works. It’s a side-by-side of a purely vector-based retrieval vs. cognee’s graph-based approach, and it’s the perfect visual to understand why these connections matter.
🎥 Watch the Demo
Traditional Retrieval: The Isolated Island Problem
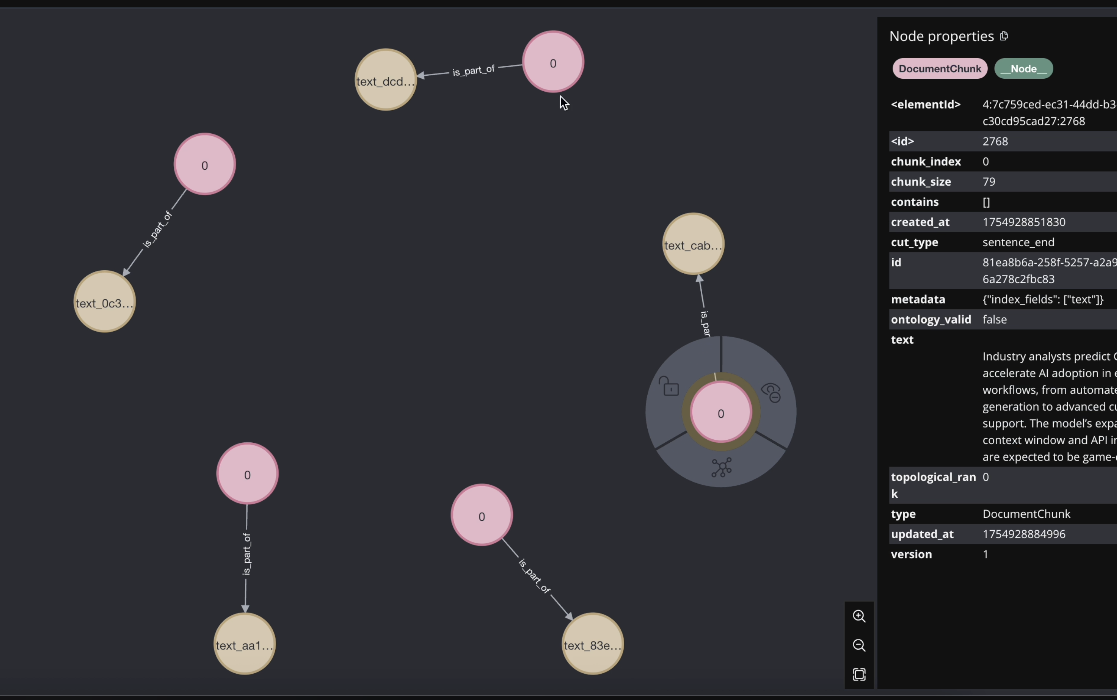
In the video, Laszlo starts with a pure vector search pipeline—no graph, no relationships. The result?
We see isolated document chunks, each one a standalone match to the query. For example:
- A press release about GPT-5’s reasoning upgrades.
- A diet study on cardiovascular health.
- A competitive cycling race recap.
Each of these pieces is found individually, with no notion of how (or if) they connect to each other.
When you’re working at scale, that’s like flipping through an encyclopedia where every page is shuffled and unrelated—you might get relevant snippets, but no coherent picture.
Adding the Graph: Context Comes Alive
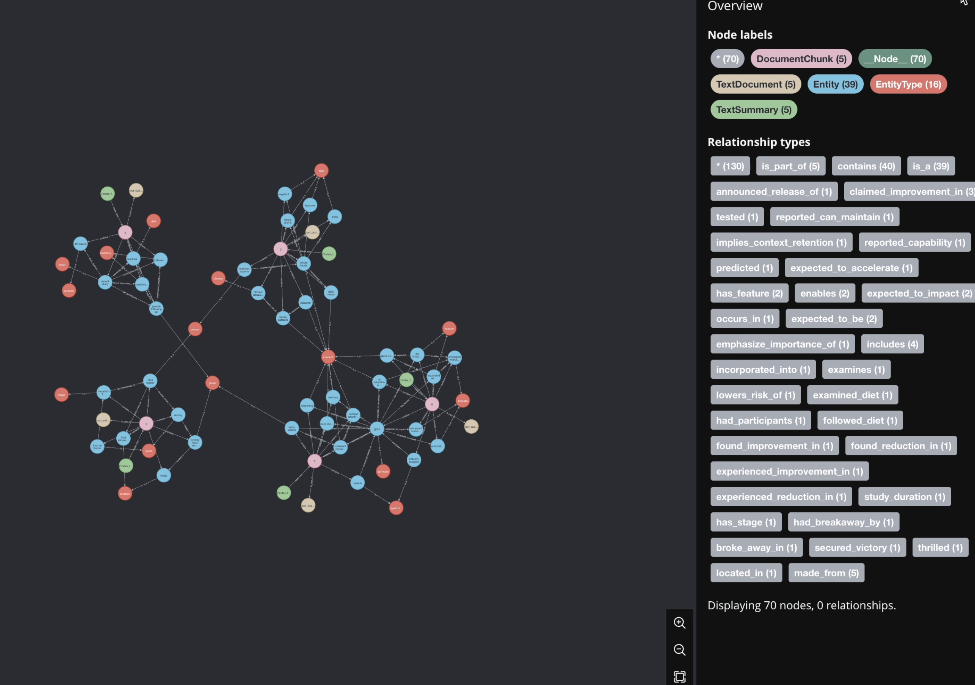
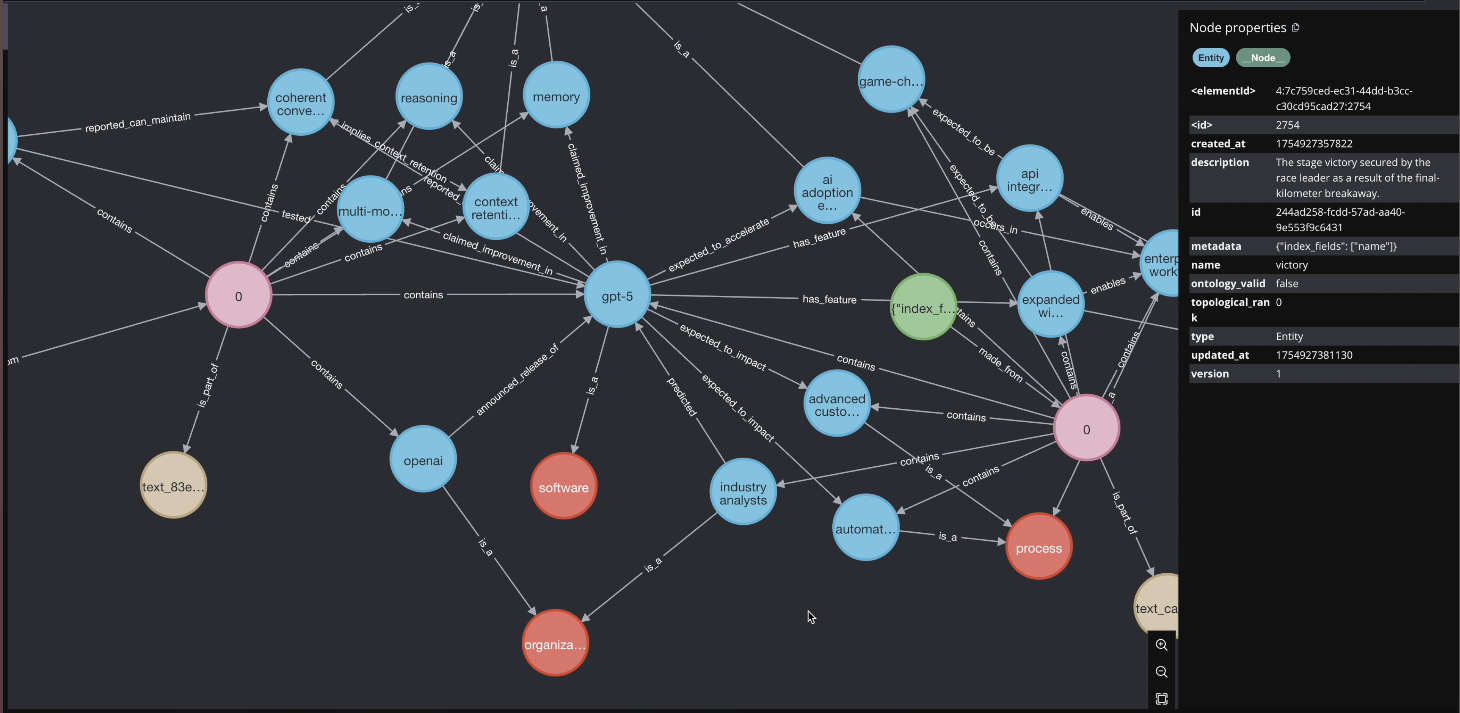
Then, Laszlo puts the graph back into the pipeline.
Now, documents aren’t just matched on similarity—they’re linked through shared concepts and entities.
Here’s what happens:
- GPT-5 articles form a strong cluster around AI advancements.
- Nutrition studies link to each other via shared topics like “Mediterranean diet” and “disease prevention.”
- Even seemingly unrelated topics, like cycling fans and plant-based diet followers, connect through the concept of groups of people.
Suddenly, the retrieval results aren’t just related to your query—they’re embedded in a web of context.
Why This Matters at Scale
When you have millions of documents, pre-computing these content-aware structural links is like giving your AI a memory map.
Instead of searching blindly through isolated facts, your system can traverse a semantic network—pulling in richer, more contextually relevant information. This is the difference between a chatbot that “knows facts” and one that can connect the dots.
Think of it as building a brain for your AI agent: every memory linked, every concept in context.
Try It Yourself
If you’re curious about the nuts and bolts, you can explore cognee on GitHub and see how we represent these relationships in our semantic graph.
You can also check out our website or drop into our Discord to chat with the team.
A graph-based approach to retrieval doesn’t just find relevant information—it understands how that information fits together. If you want AI that reasons with context, not just keywords, you’ll want to give Laszlo’s video a watch and try cognee.


