Even More Depth & Nuance: Announcing Advanced Weights for Enhanced Reasoning
Weighted Relationships: Capturing Real-Life Priorities
Most knowledge graphs treat every relationship the same. Reality doesn’t. Some connections are strong, recent, or trustworthy; others are weak or stale. Without weights, knowledge graphs flatten these differences and essential nuance disappears.
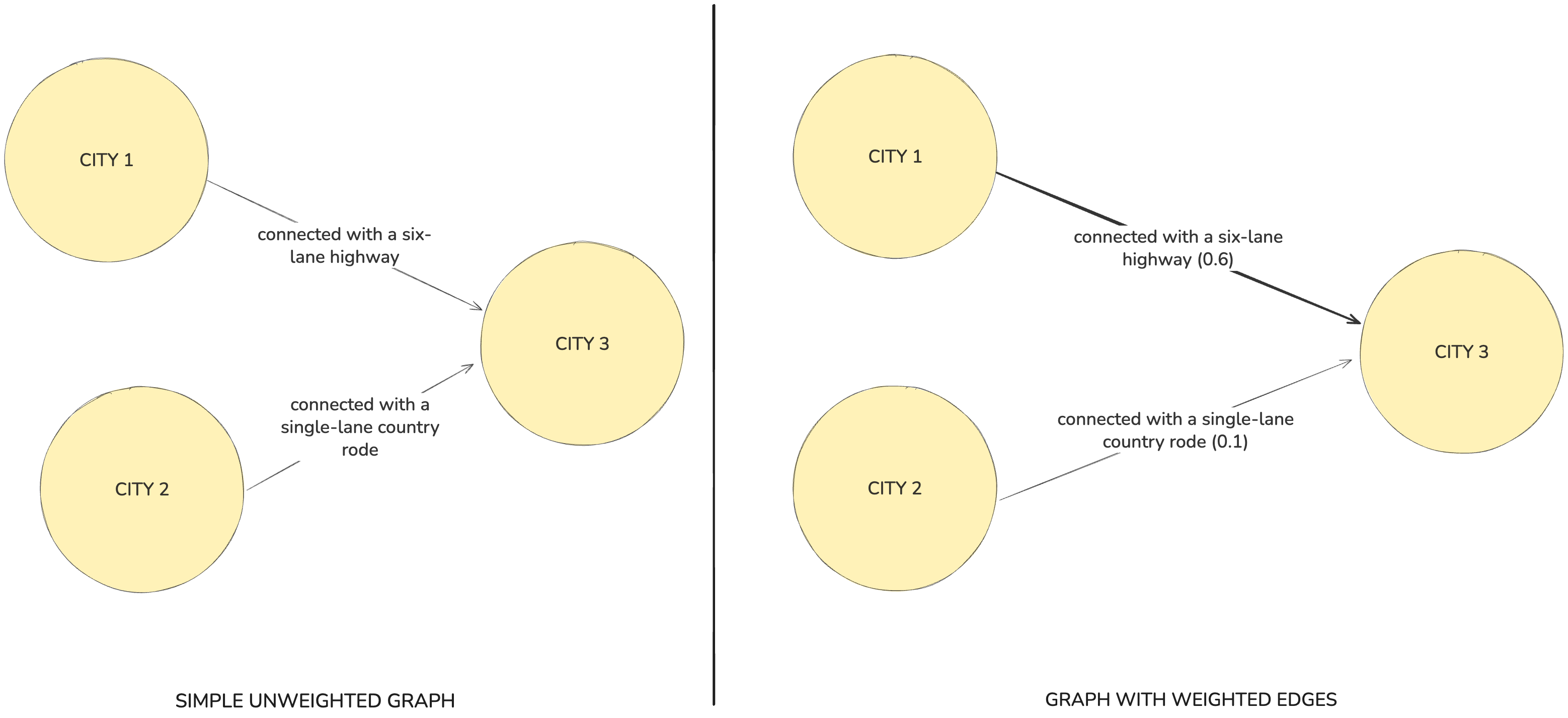
Here’s a simple analogy: two cities can both be “connected” to a third one, yet one route might be a six-lane highway while the other one is a single-lane country road. Weighting lets your graph encode that difference—so retrieval can prioritise what matters, filter noise, and reflect how information changes over time.
From open-source foundations to specific use case-tailored solutions, our mission here at cognee is to have our graphs understand more than just basic connections between data points.
In our engine, weights are first-class numeric properties—you can attach multiple named weights per item and query them like any other property. The result is a graph that expresses not just what is connected, but how strongly and with what signal.
For anyone working with complex information—whether in research, product design, or customer data—this opens the door to insights that unweighted graphs simply can’t provide.
Our Open-Source Foundations: Ready-to-Use Customizable Weights
In cognee's open source, we provide a flexible foundation for defining weights, allowing users to store richer context directly in their data. Multiple types of weights can be added to each node and edge—all saved as core properties in the graph.
The system doesn’t prescribe the categories—it gives you the freedom to model the world in the way that’s most meaningful to you. This means you get to define what counts: track "interaction frequency" and "recency" for one project, or "confidence score" and "relevance" for another.
You can see our weights at work in our auto-optimization system. It interprets natural language feedback to retrievals and assigns sentiment scores to users’ responses. These build an aggregated record of useful weights over time.
While the open-source layer doesn't yet apply them to retrieval or ranking, the structure is there for graphs that can adapt and learn based on real usage—check the feedback system docs for implementation details.
This data-centric approach is what sets the foundation apart: graphs aren’t just static fact-stores. They’re designed to hold the subtle information—confidence, importance, frequency—that will make future graph operations far smarter and more agile.
Here's how this looks in practice—a working example that shows weighted relationships between people, objects, and clothing items, complete with an interactive visualization:
On the Horizon: Advanced Weighting for Adaptive Graphs
The basics are solid, but we're pushing weights further with internally refined developments. These will make graphs more adaptive, for those needing production-grade depth and nuance.
Coming to open source:
- Document-level importance (with propagation): Soon, you’ll be able to assign importance at the moment of ingestion. That weight will flow through the graph—into the entities, relationships, and facts extracted from each document—so the graph automatically reflects which sources matter most.
- Temporal weighting in retrieval/ranking: We’re adding ways to measure how often and how recently information is being used. These frequency and recency signals will help the graph understand dynamically changing relationships and, since cognee’s graph is inherently time-aware, capture temporal patterns in the content itself.
Closed-source / bespoke solutions:
- Feedback enrichment: Beyond storage, feedback weights can also enrich the graph itself. By clustering questions and responses, the system learns which areas deserve more emphasis and automatically strengthens those connections. This mechanism is already available, but it’s part of our closed-source toolkit.
- Custom pipelines & weighted retrieval/reranking: In real-world projects, we’ve also seen the value of building domain-specific workflows, which pair well with agentic, multi-step approaches. These custom systems hint at the potential of tailored weights, though we’re keeping the details under proprietary wraps.
Together, these developments point toward a new phase: graphs that don’t just store weights, but actively use them to shape retrieval, reasoning, and discovery.
Balancing Innovation: Open Source Stability Meets Proprietary Exploration
Our philosophy has always been to give the community a stable and viable foundation. That means the core graph model and its weighting capabilities belong in open source, where they can grow with community input and be used across domains.
Meanwhile, much of our breakthroughs start in a more experimental environment that lets us iterate quickly, test ideas in real projects, and learn what really works at scale. Some of the features—like advanced retrievers or enrichment mechanisms—remain proprietary, while many others eventually mature and move into the open-source project once they’re ready for broader adoption.
In other words, open source is where stability lives, while closed source is where we push the frontier. Both are essential, and together they ensure cognee continues to be both a platform for community innovation and a product that delivers for real-world use cases.
Get Started with Weighted Graphs Today
Weighted graphs are ready in cognee's open source for foundational use, with proprietary features unlocking more in paid plans. Experiment with customizable weights to see how they refine your graphs, and join the community to contribute ideas as the product evolves.


