
Scaling Intelligence: Introducing Distributed cognee for Parallel Dataset Processing
📝 TL;DR: Distributed cognee revolutionizes processing large datasets by enabling parallel execution on remote infrastructure, slashing times while maintaining high-quality results.
Nearly all information nowadays is digital—and there’s more and more of it every day. AI has to keep pace, handling exponentially growing datasets without sacrificing retrieval efficiency or the integrity of the semantic layer. That’s why we’re introducing distributed cognee: in-engine parallel processing that lets you work through massive corpora at speed, while avoiding the typical scaling pains.
Built on our open-source core and designed for clean integration, distributed cognee keeps your AI memory robust, contextually rich, and production-ready for advanced applications—so you can build smarter, faster systems without increasing system complexity.
Why Switch to Distributed cognee?
Modern AI workflows are inundated with data, and relying on a single processing unit usually doesn’t cut it. This is especially true for tasks involving LLMs, where delays stem not just from computational power but also from response times. cognee already optimizes by parallelizing steps within its limits, but when you're constrained by local infrastructure, scalability hits a wall.
What’s the alternative?
Glad you asked. Now you can run cognee on remote infrastructure, which divides datasets into manageable chunks, each handled by dedicated processing units. This parallel approach accelerates everything from extraction to loading, making it ideal for building expansive AI memory layers and supporting agents that rely on vast, context-engineered knowledge for sequential decision-making.
Without distribution, cognification can take hours; with it, cognee scales horizontally to keep the memory layer lean and responsive. In production scenarios—such as financial analysis over gigabytes of transaction logs—parallelization delivers timely, accurate insights for the semantic layer while remaining consistent.
Getting Started with Distributed cognee
Transitioning to distributed cognee involves a bit more setup than local runs, but the payoff in speed and scale is immense. You'll need a Modal account, remote Neo4j and pgvector instances, and cognee configured accordingly. Once set, calling cognify triggers a fleet of Modal processes to handle your files in parallel. In the coming sections, we’ll walk you through the pipeline step by step.
Setting Up Modal
First off, let's cover Modal—a platform that simplifies running Python code at scale. Its autoscaling lets you spin up thousands of instances with minimal boilerplate, complete with secrets management and queues. Plus, it's cost-effective, making it perfect for distributed workloads without piling on overhead.
To get started:
- Head to Modal.com and sign up for an account.
- Install the Modal Python library by running pip install modal
- Authenticate via CLI by running modal setup
This quick process unlocks the remote execution cognee needs for distribution.
Configuring Neo4j
For your graph database, choose between a hosted Neo4j instance or a free Neo4j Aura setup—both perform well in our tests. Hosted gives more config flexibility, while Aura is easier to spin up. A locally hosted instance won’t work, as Modal containers can't access your network.
A Neo4j instance needs to be able to handle huge number of concurrent connections, so tune for high throughput with settings like these in your Docker compose:
These ensure stability for large-scale graph operations in your AI memory.
Setting Up pgvector
For vectors, we recommend hosting pgvector with tuned settings—we’ve found that self-managed solutions on AWS or Azure work reliably. Use the pgvector Docker image and configure for high connections:
This setup optimizes for the vector embeddings in your semantic layer.
Enabling Distributed Mode: Environment and Secrets Setup
With infrastructure ready, we need to setup cognee to use the remote system and file storage, and let it know that it can use Modal to run pipelines. Use S3 for files to enable distribution, then create a .env file locally and add the following environment variables to it:
Then, create a distributed_cognee secret in Modal and paste these vars from the .env in it.

Let’s Launch
To process data from your S3_BUCKET_PATH run the following command from cognee's root:
You can open the Modal dashboard and keep track of the progress in real-time. Each instance behaves like an individual cognee pipeline, outputting logs that you can see in modal dashboard.

ℹ️ Tip: If you want to experiment and customize the run, change the entrypoint.py file before running it.
Benchmarking Distributed cognee
To showcase the impact, we benchmarked on a 1GB text-heavy dataset containing multiple files.
Distributed cognee completed the full ECL process—ingesting, enriching with embeddings and entities, and loading to databases—in ~45 minutes, yielding around 46,000 entities and 133,000 relationships, all indexed in pgvector for efficient retrieval.

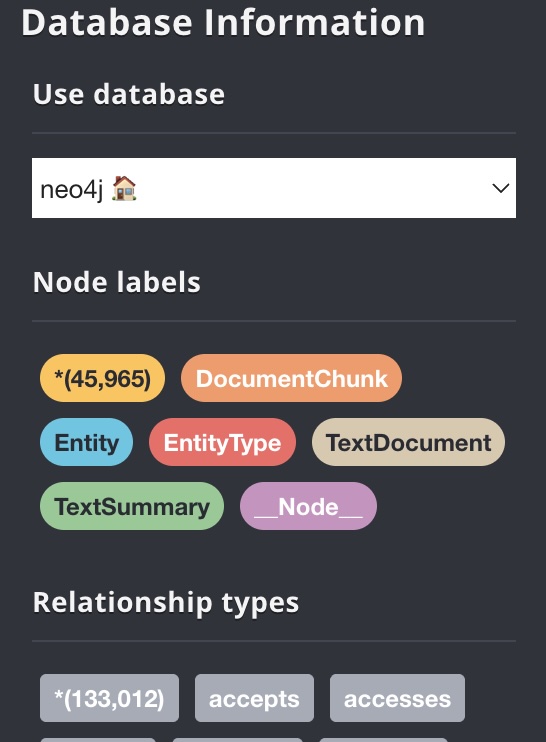
In contrast, a standard local cognee run on the same dataset took >8 hours to produce equivalent results.
This stark improvement shows the potential of distributed systems in modern data workflows, particularly for building scalable AI memory that supports rapid semantic analysis and context engineering.


