Separate memories for organization, agent and user: Support AI Agent Use-Case
"Different users, different data sources, different agents — all of them contributing to the organization's knowledge base."
Support agents are bad. Especially for deeply technical products.
But why?
Most teams do not have a support problem. They have a context problem.
Open-source AI infra projects like cognee get a lot of questions on a daily basis: bugs, feature requests, integrations, edge cases. Add paying customers on top, and suddenly engineers are spending a huge chunk of their time just answering the same questions over and over.
The first thought? Support agents.
But most support automation tools fail for a simple reason: they don't understand your system.
For that reason we decided to build something different.
Support agent with the right context
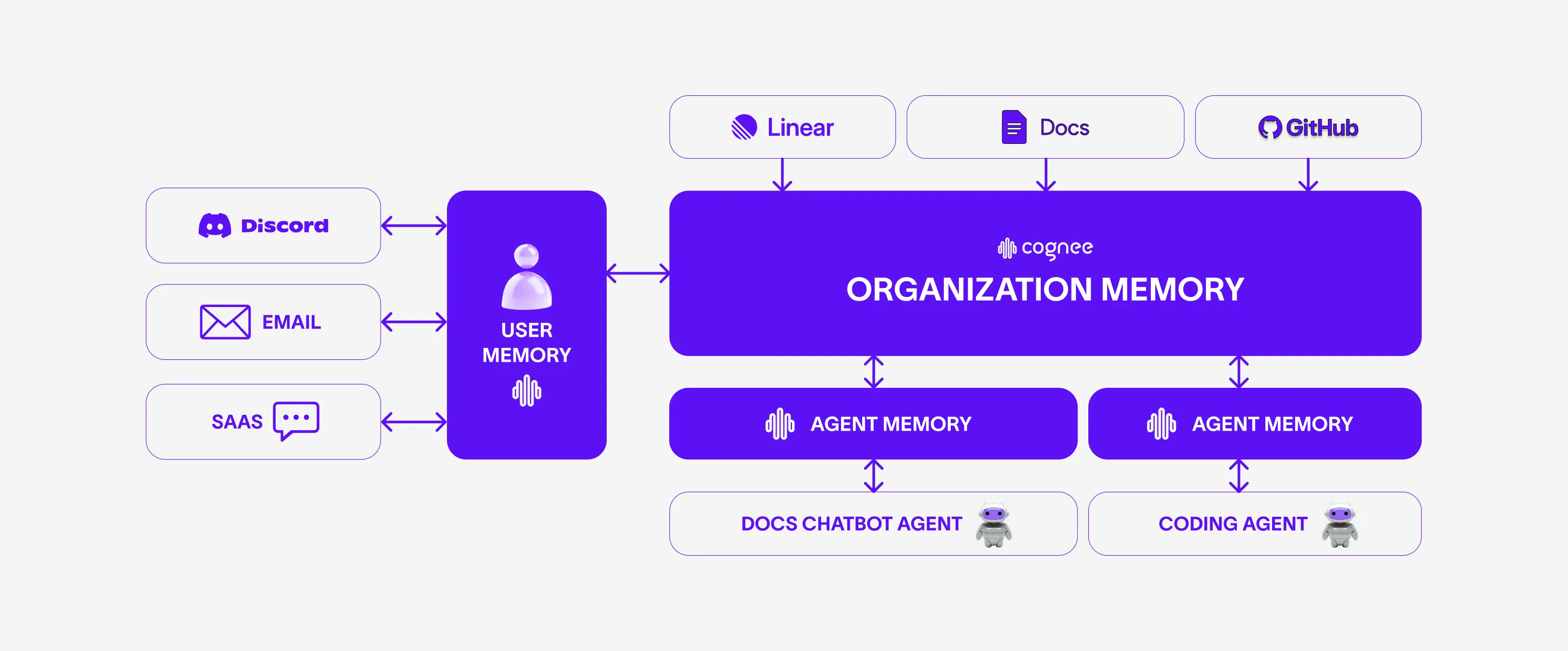
In our setup, we have a couple of different points where a user can actually ask a question: Discord, email, cloud SaaS chat, technical docs bot (Mintlify). But before jumping to how an agent answers a particular question, one first needs to solve a much more complex question:
How do you structure your organization's knowledge?
For v1 of this mini-product, we decided to use our internal Linear, our docs, and the GitHub issues of our open-source project. Additionally, we added past conversations we've had with the open-source community through various channels such as Discord and email.
Most importantly, we wanted to add coding agents that look into our codebase and reply to the deeper technical questions. That way, the support agents have the main set of ingredients your organization needs to have enough context to give as good an answer as possible.
Side note: For v2, we will also give the coding agent access to our proprietary code with our data isolation feature, to be 100% guaranteed against potential prompt injections. If context from the private repo is used, it would require special permission from an engineer in the team.
The architecture of the agentic workflow can be seen here:
Now that we've decided which data sources we are going to use, the real challenge becomes clear:
How do you organize all that knowledge in a way that is agentic-friendly?
And, as you can probably guess, the answer is:
cognee
Side note: There's a special kind of feeling that comes from using your own product to solve a problem that you personally experience.
Coding agents, user queries, chatbots, internal docs — they're all related to cognee, but their context is a bit different. For that reason, we loved our multi-scope memory feature.
Multi-scope memory
User, agent, and organization each get their own memories.
User memory
We want each user's previous interactions stored separately, so they can persist across time.
Agent memory
Coding agents are very good, but at the same time very expensive. If users keep asking the same questions — and we have to re-run everything each time — supporting the open-source community gets very costly.
Organization memory
Individual users and individual coding agents are important, but collectively they mean so much more. The whole point of the context graph here is to combine all these users, all these agents, and all the internal documents at one core layer — and that layer becomes the organization's knowledge base.
Combining those three, you get all the main insights of every single one. Coding agent execution #123 from user #999 can help resolve agent execution #789 from user #001 more quickly and more efficiently. All the learnings and insights are shared with your permission system using our accessibility feature.
What's of high importance here is to think of such a system not only as knowledge sharing, but also as a way to get a better system over time and build your moat. For every single interaction, you have user feedback: "did you understand the question appropriately?" — and by examining those in a later phase, you know exactly what your users want and what you want to build next.
But with cognee you can do much more than just structure your knowledge. You need to keep the organization's knowledge base dynamic, so it always contains the most up-to-date information. Old requests and answers will be deleted from the memory as time goes on, and the most recent ones will be weighted higher.
Next step
We built this system to help us internally with all the questions we are receiving on a daily basis. However, since we still want a human-in-the-loop process to assess the quality of such answers, as of today it just gives us recommendations. If you want it to reply automatically, you can just turn on the permission on Discord.
Take action
Improving and scaling support for our open-source community is amazing — but we can do much more than that. We want to act upon this.
So we are going to integrate with the Linear MCP to create new issues based on the user's questions. And from there, you know the drill:
Linear issue → coding agent → coding/engineer review → PR → merge → reply to the user that we just solved the question they asked 10 minutes ago.
Stay tuned for big updates
Let us know if you want to try this mini-project yourself for your own project.
- 💬 Join us on Discord for support and discussion.
- ⭐ cognee on GitHub — star the repo and explore the source.


