Inside cognee 1.0: Memory-Native APIs for Production Agents
The difficult thing with agent memory was never expanding storage for the embeddings — it was getting memory to improve as it's used, so an agent doesn't just collect more context, but becomes less likely to make the same mistake twice.
That's what we've been working on here at cognee. The API, SDKs, retrieval layer, migration path, and Cloud support in cognee 1.0 all have the same purpose: giving agents more usable memory.
We kept hearing the same questions from people moving agents into production: How do I give an agent memory in one line? How do I stop it from making the same mistake? Can I use memory from TypeScript, not just Python? Can I bring the memory I already have?
cognee 1.0 is our answer to all of that: four verbs, a feedback loop, and memory that can run wherever your agents do.
A memory-native API
The API is now built around how agents actually use memory: four verbs, the same in the Python SDK, HTTP API, and over MCP.
remember, recall, improve, and forget replace the older add, cognify, and search flow. The lower-level pipeline is still there for those who need it, but most agents can now work through the memory-native interface instead.
Here's how everything fits together.
remember()

Hand cognee plain text and it pulls out the entities and relationships, turning a sentence into a connected memory graph. You don't write data into a schema — you just give it words, and it builds something an agent can reason over and links it into what it already knows.
This function stores new information and connects it to the memory graph. That can be a document, a conversation, a correction, a tool result, or a statement you want the agent to keep.
The
session_idis used when memory belongs to a specific interaction. If feedback is produced through an agent integration, cognee handles this automatically: the feedback first lands in session memory, then becomes part of permanent memory. If you're adding feedback or corrections yourself, you pass the session ID along with the Q&A entry ID (qa_id) so cognee knows exactly which answer that signal belongs to.
recall()

Ask a question in plain language and get an answer grounded in the graph, not guessed. cognee walks the relevant path — cognee → based in → Berlin — and returns "cognee is based in Berlin," traceable to the facts it stored rather than invented.
This function retrieves the most relevant memory for the current question or task. It can use graph structure, retrieval signals, and previous feedback to decide which memories should matter most.
Feedback comes after an answer has been judged. Once an agent's answer is confirmed, corrected, or rejected, that judgement becomes a signal attached to the memory used to produce the answer.
Confirmed memories can become stronger. Corrected or misleading ones can be pushed down. Over time, cognee keeps re-weighting memory from use, feedback, importance, and frequency.
improve()

Memory that sharpens itself as it's used. cognee combines facts it already holds — Vasilije → cognee and cognee → Berlin — to infer a new connection, Vasilije → Berlin, so answers that would have needed a multi-hop lookup are already there. The connections it adds stay traceable to the facts behind them.
In cognee 1.0, the self-improvement loop runs by default (cognee.remember(conversation, self_improvement=True)).
Still, you can call improve() when you want more granular control: to trigger improvement manually, scope it to a dataset, or make the process explicit inside your own workflow.
forget()

Delete a specific memory and its links cleanly. Tell cognee to forget Vasilije and that node plus its "founded" edge dissolve, while the rest of the graph stays intact — so you can honor removal requests or drop stale facts without rebuilding everything.
This function removes memory that's no longer useful. That can mean clearing a dataset, removing outdated information, or deleting memory tied to a specific scope.
These four verbs encompass the full memory lifecycle: commit what matters to memory, retrieve it when needed, learn from how it was used, and remove it when it should be gone.
Memory that improves, not just grows
This is the centerpiece of the release.
Most memory tools are built to append — this allows stale information to keep resurfacing even after an agent has been corrected. With cognee 1.0, memory is continuously re-weighted as agents use it.
The improvement loop is fed by three signals:
- Feedback applies after an answer has been judged. The feedback is attached to the nodes, edges, and evidence that contributed to the answer, so corrected memories can rank lower and confirmed ones can rank higher.
- Importance is set at ingestion, so the runbook outweighs the Slack dump.
- Frequency accumulates with use, so the paths an agent actually relies on can reinforce themselves over time.
Retrieval, judgement, feedback, importance, and frequency all feed the loop, so memory gets better rather than just bigger.
The effect is fact reconciliation. If an answer is corrected, that correction should not vanish when the chat ends — it should become part of what future retrieval sees so that the agent eventually stops repeating the mistake.
That's what's necessary for production-ready memory. Everything that follows — the decorator, retrieval layer, SDKs, migration path, and Cloud support — exists to get this memory into your agents and keep it trustworthy.
Drop-in agent memory
The fastest way to put self-improving memory inside an agent is using a single decorator.
It wires memory in end-to-end, retrieving relevant context before your function runs, injecting it into the call, and persisting the trace afterward, so the agent's own history becomes queryable memory. One line, no other changes needed.
Retrieval you can trust
Memory is only as good as what it gives back.
cognee 1.0 combines graph traversal, vector search, and BM25 lexical retrieval. Hybrid results are fused with reciprocal rank fusion, and queries can be routed to the retrieval method that fits them best.
Answers now carry evidence references. They cite the chunks they were built from, so an agent can show its work and you can audit why it said what it said. You can check more information here.
TypeScript, not just Python
cognee 1.0 includes a TypeScript SDK with the same core memory verbs.
The core verbs are now available across Python, Rust, and TypeScript.
Import your existing memory
Switching tools should not mean abandoning your data. remember accepts provider sources directly, so existing memory can be brought into cognee instead of having to rebuild it from scratch.
And you can take it back out at any time, via the open COGX format or standard graph formats.
COGX is a versioned, portable memory archive. It's designed to preserve the graph structure, metadata, provenance, and retrieval-relevant state needed to move memory between systems.
No lock-in was our design constraint, not a marketing line.
From local to Cloud in one line
The same code can run against a managed instance. Point the SDK at cognee Cloud and every call routes there.
You can also push a local dataset to Cloud: this command exports your local graph as a COGX archive and lands it in Cloud with no re-extraction, so you can move from a laptop to production without rebuilding the memory pipeline. Cloud documentation can be found here.
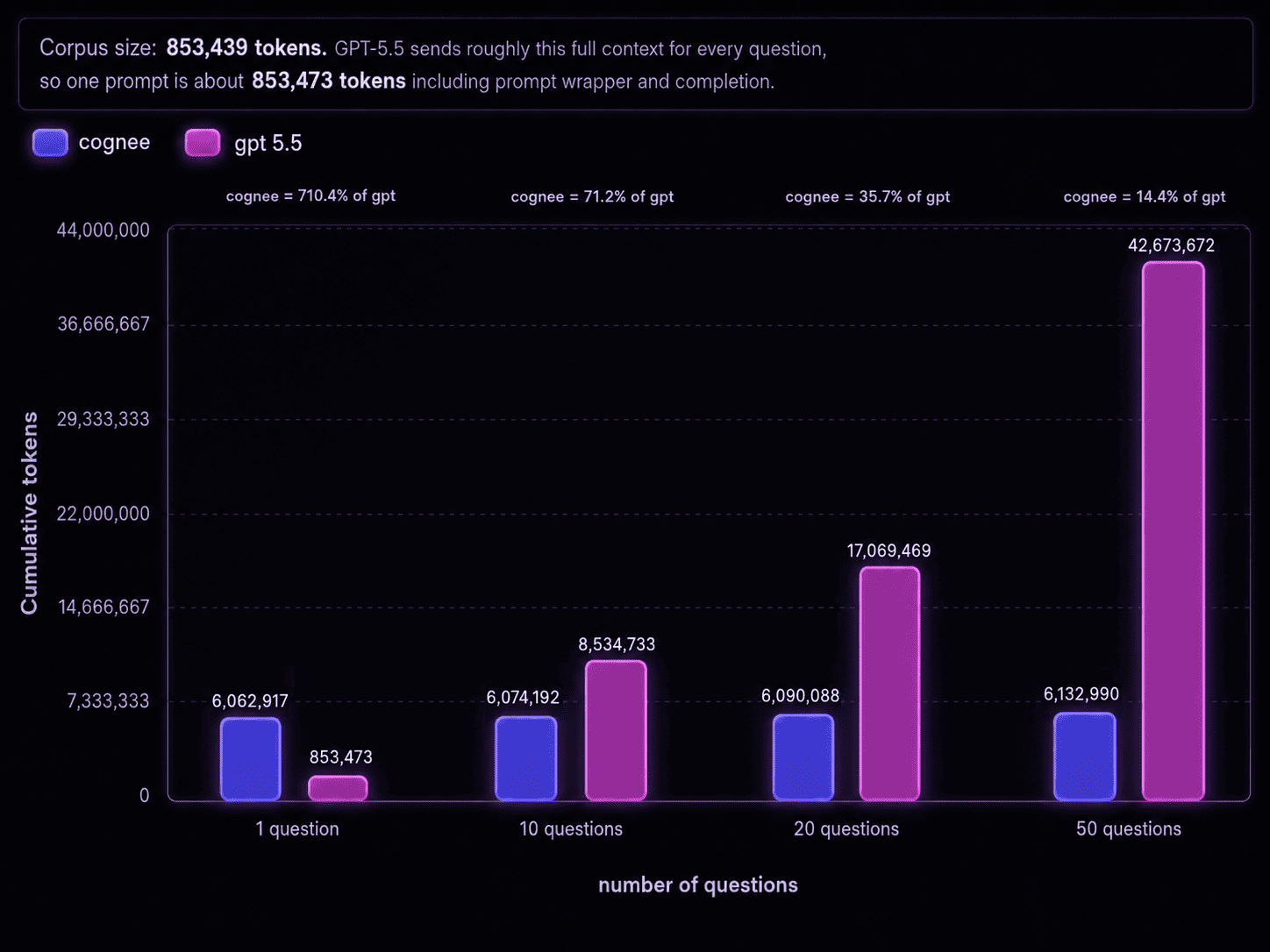
Efficient at scale
We measured the token cost of answering a set of questions against a fixed synthetic corpus two ways: cognee (ingest once, then retrieve), and a full-context GPT-5.5 baseline (resend the whole corpus on every question).
Applying a single blended rate of about $9.84 per million tokens to both, at 50 questions GPT-5.5 runs up to ~$420 and cognee ~$60, with cognee using roughly 85% fewer tokens than GPT-5.5.
What comes next
We think the next step is memory that's not just attached to agents, but actively shaped by how they work: corrections, usage patterns, task context, and domain-specific schemas.
The four verbs are the floor, not the ceiling. remember, recall, forget, and improve give agents a stable surface for memory. From there, the memory layer can become more adaptive, more portable, and more aware of the workflows it supports.
Start locally, connect through MCP, or use a free Cloud key.
What shipped in 1.0
| Area | Change | PR |
|---|---|---|
| API | Memory-native remember / recall / forget / improve | #2591, #2596, #2601 |
| API | Typed return shapes for recall | #2691 |
| API | Dataset scoping across operations | #2797, #2777 |
| API | forget with graph-only mode and flexible identifiers | #2734, #2874 |
| API | Custom graph models to ground memory in your schema | #2916 |
| Self-improvement | Feedback weights on graph nodes and edges | #2266 |
| Self-improvement | Feedback weights influence retrieval scoring | #2427 |
| Self-improvement | Importance-weighted ingestion | #2438, #2447 |
| Self-improvement | Frequency weights via session API | #2746 |
| Agents | @cognee.agent_memory decorator and quickstart | #2533, #2678 |
| Agents | cognee.agents namespace and CLI with permissioning | #3003 |
| Migration | Import from Mem0, Zep, and Letta; export to portable COGX | #3024 |
| Retrieval | Hybrid retrieval with graph, vector search, and RRF | #3014, #3049 |
| Retrieval | BM25 lexical retrieval | #3010 |
| Retrieval | Question-decomposition retriever variants | #2574 |
| Retrieval | Evidence references in completion answers | #3016 |
| Retrieval | Global context index with graph bucketing | #2848, #2886 |
| Sessions | SQL session cache with SQLite default and Postgres support; no Redis required | #3028 |
| Skills | GET /v1/skills list endpoint and publisher metadata | #3071 |
| Storage | Postgres as a full graph backend with multi-user isolation | #2584, #2825 |
| Storage | Ladybug replacing Kuzu as the default embedded graph database | #2755 |
| Ops | One-click deploys for Modal, Railway, Fly, and Render | #2296 |
| Ops | Python 3.10–3.14 support | — |
See the numbers for yourself


