cognee on-device: Bringing Agent Memory to the Edge
Memory shouldn't have to live somewhere else
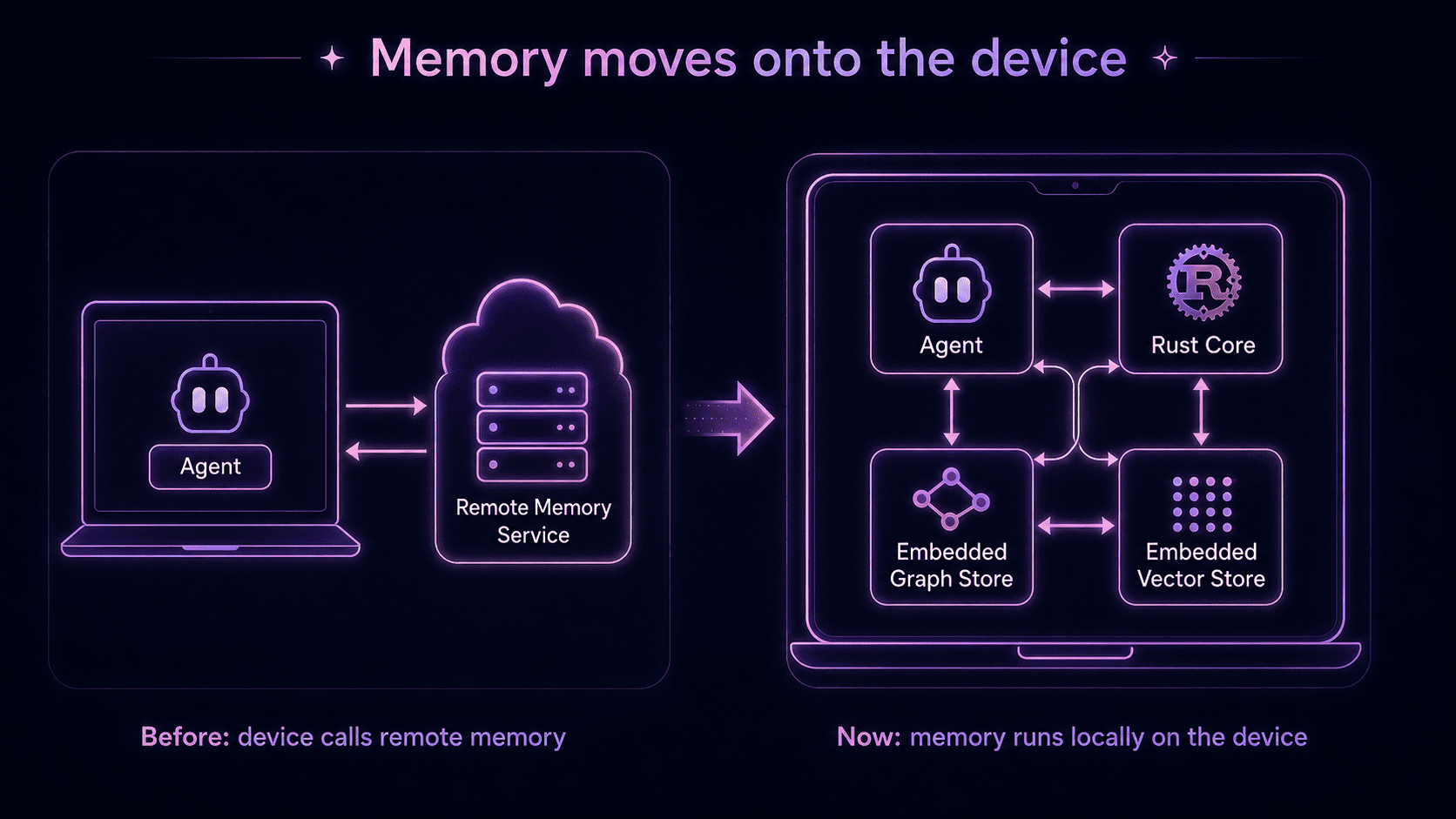
When we started cognee, memory lived in a datacenter.
You sent your data somewhere, it got processed somewhere, and the answers came back from somewhere. This works well enough when the agent is a web app, but it collapses the moment the agent lives on a phone, in a robot, or on a laptop with no connection.
That's why we rebuilt the cognee core in Rust.
Not because rewriting things is fun (it isn't), but because we think memory needs to go where agents live — and more and more, that's starting to mean devices without datacenter-shaped hardware.
The Rust core builds on the memory-native API we introduced in cognee 1.0.
Older versions of cognee were organized around our pipeline commands: add, cognify, and search. But agents don't think in pipelines, so in 1.0 we replaced them with the verbs they actually use.
rememberrecallforgetimprove
No heavy infrastructure required. Just the operations agents need, running wherever they run.
Graph, vectors, and recall on the device
The Rust core runs the local memory pipeline end-to-end: ingestion, graph construction, embedding, and search.
It uses an embedded graph store and an embedded vector store, so there's no separate memory service to stand up. You can specify your models, choose your data, and run the memory layer locally.
The default path is CPU-first. GPUs can help as workloads grow, but small local memory jobs shouldn't need one.
This buys you three things:
- Your data can stay on the device.
- The core is small enough to run where a full stack wouldn't.
- The same memory model can now reach places the Python stack was never able to.
This is what I mean when I say memory should be available wherever agents run. In cognee 1.0, that doesn't just mean Cloud, self-hosted deployments, or a single Postgres. It also means the edge.
How the Rust core scores
We measured cognee-rs against the Python SDK, then ran the local pipeline on-device.
The important thing to understand before we get into the numbers is that Rust can't magically make a remote LLM faster. In LLM-heavy stages, a lot of the time is still spent waiting on the model provider, meaning that ingestion results can vary depending on the corpus, model path, and provider latency.
Where Rust's advantages can be noticed most clearly is around the memory engine itself: startup, orchestration, search, and local retrieval.
In the OpenAI-backed runs, Rust search returned in 0.23s on the small document set and 0.27s on War and Peace, compared with 2.66s and 4.03s for the Python SDK. When we removed model latency with a Mock LLM, Rust was faster across both ingestion and search, because the benchmark was measuring the engine more directly.
The number I personally care about most, though, is the on-device result.
We ran the local pipeline on a Samsung Galaxy S24 Ultra using Alice in Wonderland as the input corpus. The full run completed in 139.12s, with most of that time spent building memory. Once the memory was built, retrieval stayed in the low-single-second range depending on strategy, with chunk and summary search taking around 1s.
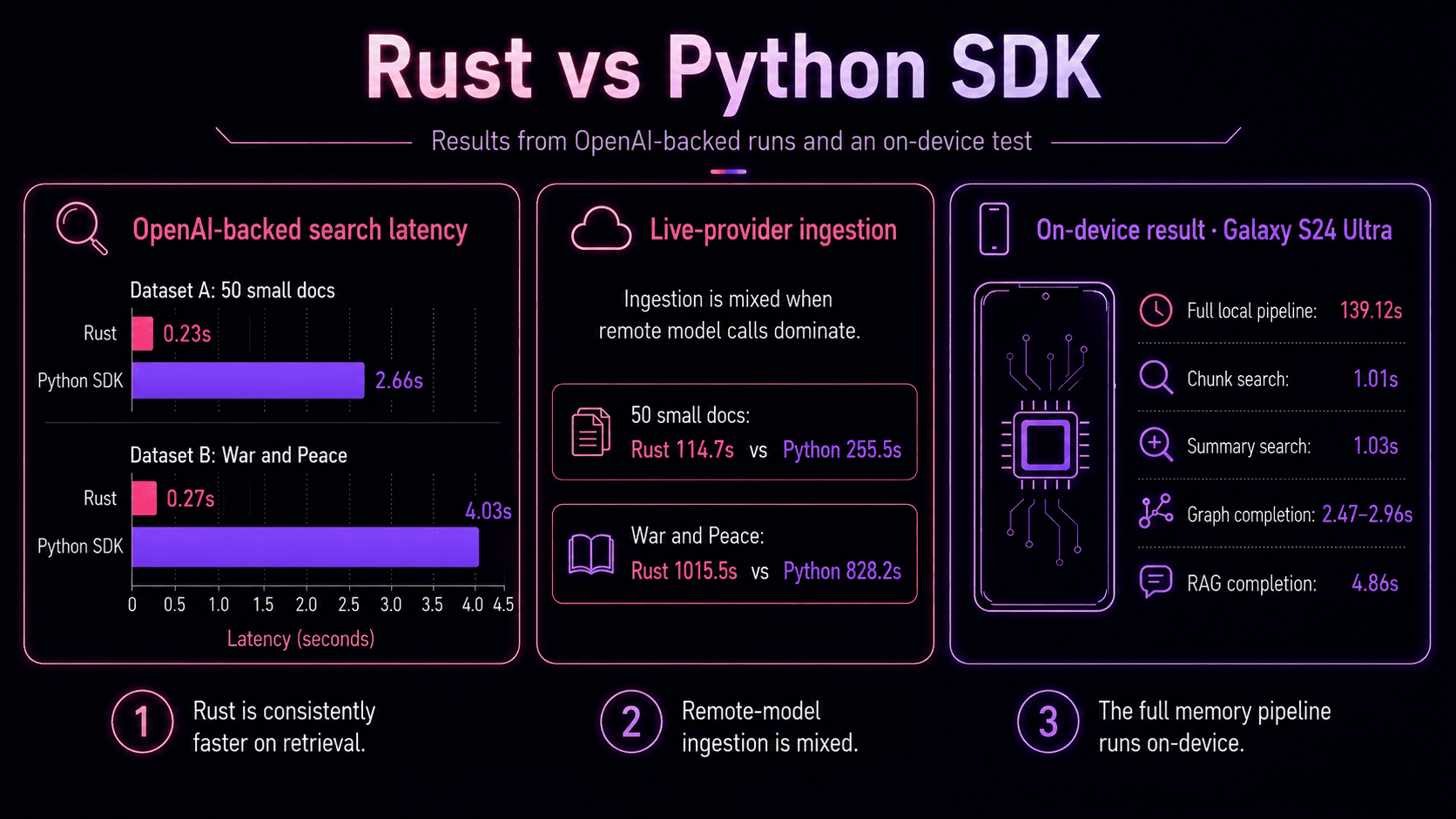
That's the point of cognee-rs.
Not every workload becomes faster just because it runs in Rust. But the full memory pipeline — ingest, graph construction, embeddings, indexing, and retrieval — can now run locally on a consumer device, without a server-side memory stack, enabling agent memory to follow agents onto the device.
Want more details? Get the full benchmark tables, model setup, and methodology in the tech report below.
What cognee-rs is, and what it isn't
cognee-rs is the cognee core made portable: small enough to run locally, flexible enough to use the models and data you choose, and connected to the same memory lifecycle as the rest of cognee.
It's us moving toward the vision that memory should be open, owned, and available wherever agents run — with the Rust core making sure "wherever" includes devices.
cognee-rs is not a replacement for the Python SDK. Python is still the easiest way to run cognee in cloud pipelines, research workflows, and full-featured backend systems.
The Rust engine is for the places Python was never going to reach comfortably: phones, robots, embedded machines, sensors, offline environments, and hardware where memory needs to stay close to the agent.
Local memory for local agents
Agents are leaving the datacenter and showing up in phones, cars, wearables, robots, and embedded hardware — where the network is unreliable and the data is often private. Memory has to follow them there.
A robot shouldn't need to call a remote service to remember the room it just mapped. A phone agent shouldn't have to send private context away just to retrieve something it already learned. A laptop agent shouldn't become useless the moment the connection drops.
The Rust core is a small piece of code doing a large job. It brings agent memory closer to the agent itself: local, portable, and still built around the same four verbs.
One brain. Every agent.
Even the ones that never touch a server.
We're shipping cognee-rs as part of cognee 1.0. Try running it somewhere small, weird, or offline, and let us know what breaks.
— Vasilije Marković
Founder and CEO, cognee
Go deeper on cognee-rs


