
How Cognee Builds AI Memory

I started cognee three years ago because I needed personalized, persistent AI memory for users in a B2C application. Existing tooling around vector databases required manual management of collections, embeddings, updates, and deletions. Unfortunately, there was no reliable abstraction for structured memory, no support for long-term evolution, and no principled way to connect semantic retrieval with reasoning.
Three years later, cognee has a production-grade Python SDK running over one million pipelines each month, adopted by more than 70 companies including Bayer, University of Wyoming, Dilbloom, and dltHub. The scope expanded well beyond the original idea of "better RAG." What emerged instead is a knowledge engine that treats memory as a first-class systems problem.
Our vision has been shared by Pebblebed, 42CAP, Vermilion Cliffs Ventures and angels from Google DeepMind, n8n, and Snowplow in our latest $7.5M seed round.
As part of our major announcement, I wanted to reiterate what cognee is all about. Let’s see what cognee excels at, and what we plan on doing in the next year.
The Core Pipeline
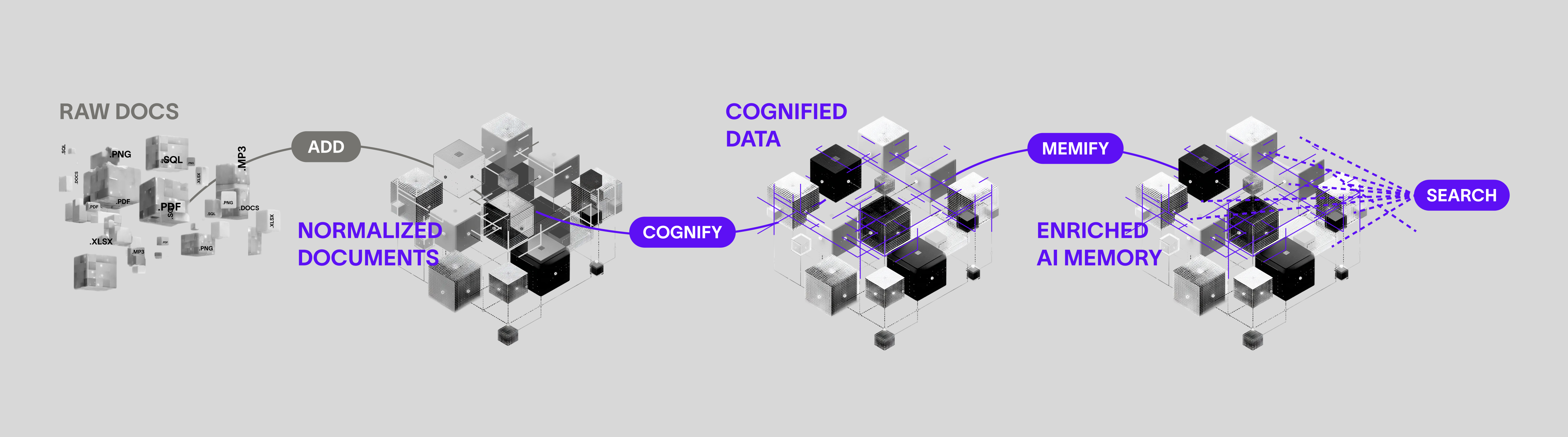
Cognee's API has four operations. Everything is async.
add ingests data. It takes files, directories, raw text, URLs, or S3 URIs. It supports 38+ formats (PDF, CSV, JSON, audio, images, code). Content is normalized to plain text, hashed for deduplication, and organized into datasets with ownership and permissions.
cognify builds the knowledge graph. This is the core operation. It runs a six-stage pipeline: classify documents, check permissions, extract chunks, use an LLM to extract entities and relationships, generate summaries, then embed everything into the vector store and commit edges to the graph. Only new or updated files are processed on re-runs.
memify refines the graph after ingestion. It prunes stale nodes, strengthens frequent connections, reweights edges based on usage signals, and adds derived facts. This is where cognee's self-improvement happens: memory is not static storage, it's an evolving structure that adapts based on feedback and interaction traces.
search queries across both vector and graph layers. Cognee ships 14 retrieval modes, from classic RAG to chain-of-thought graph traversal. More on that below.
Architecture: Three Stores, One Engine
Cognee is a graph-vector hybrid. It unifies three storage layers into a single memory engine:
- Graph store for entities, relationships, and structural traversal. Default: Kuzu. Also supports Neo4j, FalkorDB, Amazon Neptune, Memgraph.
- Vector store for embeddings and semantic similarity. Default: LanceDB. Also supports Qdrant, pgvector, Redis, DuckDB, Pinecone, ChromaDB.
- Relational store for documents, chunks, and provenance tracking. Default: SQLite. Also supports PostgreSQL.
The defaults are all file-based (SQLite + LanceDB + Kuzu), so there's zero infrastructure to set up. pip install cognee and an OpenAI key gets you running.
The fundamental unit is the DataPoint, a Pydantic model that carries content and metadata. You can define custom DataPoints to control which fields get embedded:
Entities, chunks, summaries, and relationships are all DataPoints. The graph and vector stores stay linked: every node in the graph has a corresponding embedding, so you can move between semantic similarity and relational traversal without losing coherence.
Session and Permanent Memory
Cognee separates memory into two layers. Session memory operates as short-term working memory for agents. It loads relevant embeddings and graph fragments into runtime context for fast reasoning. Permanent memory stores long-term knowledge artifacts: user data, interaction traces, external documents, and derived relationships. These artifacts are continuously cross-connected inside the graph while remaining linked to their vector representations.
In practice, this means you get conversational context that persists:
14 Search Modes
Not every query needs the same retrieval strategy. Cognee gives you 14 modes:
| Mode | What it does |
|---|---|
| GRAPH_COMPLETION | Graph-aware Q&A: vector hints find relevant triplets, LLM answers grounded in graph structure |
| RAG_COMPLETION | Classic retrieve-then-generate over text chunks |
| GRAPH_COMPLETION_COT | Chain-of-thought reasoning over multi-hop graph traversals |
| GRAPH_COMPLETION_CONTEXT_EXTENSION | Iterative context expansion for open-ended queries |
| GRAPH_SUMMARY_COMPLETION | Uses pre-computed summaries combined with graph context |
| TRIPLET_COMPLETION | Triplet-based (subject-predicate-object) retrieval with LLM completion |
| NATURAL_LANGUAGE | Translates natural language to Cypher, executes against the graph |
| CYPHER | Run Cypher queries directly |
| CHUNKS | Raw passage retrieval via vector similarity |
| CHUNKS_LEXICAL | Token-based lexical chunk search (Jaccard similarity) |
| SUMMARIES | Search over precomputed summaries |
| TEMPORAL | Time-aware graph search with temporal entity extraction |
| CODING_RULES | Code-focused retrieval from indexed codebases with rule associations |
| FEELING_LUCKY | LLM auto-selects the best mode for your query |
The default, GRAPH_COMPLETION, is where cognee differs most from vanilla RAG. Instead of returning the top-k chunks by cosine similarity, it uses vector search as a hint to find relevant graph triplets, then traverses the graph to build structured context before generating an answer.
Multi-Tenancy and Isolation
Your apps and agents need logical division. This is why memory graphs can be instantiated per user, per group, or as shared public graphs. This is not just namespace separation at the vector level. Isolation happens at the graph and trace level, with dataset-level permissions (read, write, delete, share):
Multi-tenancy is supported across pgvector, Neo4j, Kuzu, and LanceDB.
Agent Framework Integrations
Cognee plugs into the agent frameworks you're already using. Each integration exposes add_tool and search_tool that you hand to your agent:
LangGraph:
OpenAI Agents SDK:
Claude Agent SDK (via MCP):
There's also a standalone MCP server for Cursor, Claude Desktop, and Cline.
Benchmarks
We benchmarked cognee against Mem0, Graphiti, and LightRAG on 24 HotPotQA multi-hop questions, 45 repeated runs on Modal Cloud. All evaluation code is open source.
| Metric | Cognee | With CoT |
|---|---|---|
| Human-like correctness | 0.93 | +25% |
| DeepEval correctness | 0.85 | +49% |
| DeepEval F1 | 0.84 | +314% |
| DeepEval EM | 0.69 | +1618% |
Base RAG scores 0.4 on the same correctness metric. The biggest gains come from chain-of-thought graph traversal, where multi-hop reasoning over explicit relationships outperforms flat retrieval.
What Comes Next
Cognee has moved from being an abstraction layer over vector databases to becoming a system for structured, persistent, and adaptive memory. The focus is no longer just retrieval quality, but the engineering of context itself: how memory is represented, isolated, evolved, and made computationally usable for reasoning agents.
With the seed round, we're investing in three research directions.
Adaptive retrieval via trace optimization. We're moving from fixed graph traversal strategies to adaptive retrieval based on the concept of a retrieval trace, the ordered sequence of nodes visited during query resolution. Instead of applying a single traversal heuristic to all tasks, the system will learn task-dependent traversal policies. For constraint-satisfaction queries (e.g., logistics feasibility), the optimal trace should prioritize constraint nodes early. For explanatory queries (e.g., root-cause analysis), the trace should encourage broader exploration and multi-branch evidence aggregation. The objective is to learn traversal strategies that optimize performance for specific use-case classes rather than relying on static graph-walking logic.
Learning and inference-time optimization of graph traversals. Two complementary mechanisms. First, reinforcement learning will iteratively optimize traversal policies based on performance feedback, using correctness signals from labeled query-answer pairs to improve trace selection over time. Second, inference-time optimization will dynamically evaluate multiple candidate traces and select the most promising ones based on graph-derived metrics such as node centrality, structural diversity, or coverage. Together, these approaches introduce both offline policy learning and online trace selection to improve retrieval quality and efficiency.
Neuroscience-inspired embedding design. We want to do more with embeddings. The algorithmic design will draw inspiration from cognitive neuroscience models of memory retrieval and reinforcement learning frameworks for planning and rollout-based inference, grounding the system in both empirical evaluation and biologically informed retrieval dynamics.
On the product side: cloud platform, a Rust engine for on-device memory, multi-database support, user database isolation, and 30+ new data source connectors shipping in Q1 and Q2.
Get Started
You don’t need any infrastructure to see how cognee works locally. The defaults (SQLite + LanceDB + Kuzu) run embedded and with minimal resource expenditure. You can swap in Neo4j, Neptune, Qdrant, or pgvector when you're ready to scale.
Cognee Cloud: https://platform.cognee.ai/
GitHub: github.com/topoteretes/cognee (12,000+ stars, Apache 2.0)
Docs: docs.cognee.ai
Research: Optimizing the Interface Between Knowledge Graphs and LLMs for Complex Reasoning
Related technical deep dives
If you want to go deeper into the pieces behind production AI memory, these articles cover the adjacent engineering problems:
- AI memory evals — benchmark setup and scoring details for memory systems.
- AI memory tools evaluation — a practical comparison of memory tools and tradeoffs.
- Knowledge graph query answering with cognee — how graph retrieval supports multi-hop answers.
- Model Context Protocol and cognee LLM memory — how MCP connects agent tools to persistent memory.
- Ontology AI memory — why typed schemas matter for stable memory.
- Why agent memory breaks — common failure modes in agent memory systems.
- Context engineering era — why context design became infrastructure work.
- Graph databases explained — the database concepts behind relationship-aware retrieval.
- Knowledge graph myths — where graph systems are useful and where they are overkill.
- Vectors and graphs in practice — how vector and graph retrieval complement each other.


