
LLM vs Generative AI: Comparing Models, Memory, and Architecture

TL;DR:
- Generative AI is the broad category: AI systems that create new content, including text, images, audio, video, code, and synthetic data.
- Large language models (LLMs) are one type of generative AI model, built to understand and generate human language.
- GPT is one well-known family of LLMs, not a synonym for generative AI or for every AI chatbot.
- The terms overlap, but they are not interchangeable. Generative AI describes what a system does; LLM describes a language-focused model inside that category.
- For builders, the bigger question is architectural: whether the model has the right context, retrieval, memory, and grounding to produce answers that are not just fluent, but correct.
People will often say "generative AI" when they mean ChatGPT. Or "LLM" when they mean any AI system with a text output. Or "GPT" when they mean the whole category. While this conflation makes little difference in regular conversation, when it comes to choosing models, designing a product, or explaining to a stakeholder what your system actually does, preciseness is much more consequential.
This ambiguity has reasonable origins. Generative AI and large language models landed in the public eye at roughly the same time, almost always through conversational interfaces. For most people, the first real encounter with generative AI was typing something into a text box and getting a fluent reply back.
So the interface became synonymous with the category, and the chatbot (GPT for most people) with the technology. That's why the generative AI vs LLM distinction is worth making clearly — for understanding the relationship between a category of systems and a specific model type inside it.
Here's a high-level overview before we get into the nitty gritty of it: generative AI is a broad term for AI systems that create content in a range of formats: text, images, code, audio, video, or some combination. On the other hand, a large language model, or LLM, is a specific type of model with training on vast amounts of text and code to be able to "understand" and generate human language.
So the question of "LLM vs. generative AI" isn't really about a competition between two rival technologies — it's about how one model type (LLM) relates to the broader technological category it belongs to (gen-AI).
If you're designing something like a customer service assistant, an internal knowledge tool, a coding agent, or a file processing workflow, you need to know which part of your system handles language generation, which part retrieves information, which part stores memory, and which part keeps the model grounded in current data.
"We use AI" answers none of that.
"We use an LLM with retrieval, a knowledge graph, and a memory layer" starts to describe an actual architecture.
Gen-AI Is the Tree. LLMs Are Some of Its Branches.
Generative AI is an umbrella term for any machine learning system that produces new outputs — written, visual, auditory, structured, or multimodal — from patterns learned during training. The defining feature here isn't the format but rather the act of generation itself.
Generative AI systems can be trained on nearly anything: text, images, audio, video, code, 3D assets, biological sequences, structured records, or combinations of those. The training data depends on the intended output.
LLMs are generative AI models focused specifically on language. They use neural networks trained on large amounts of books, web pages, documentation, code, articles, Q&As, and other text-based material in order to process natural language, predict likely continuations, and produce responses that fit a given prompt or task.
Through their training, the model learns patterns in grammar, meaning, style, reasoning, software syntax, and domain-specific language, which makes them useful for writing, summarization, translation, question answering, code generation, customer service, research assistance, and agentic workflows.
So:
- Generative AI is the broader category.
- LLMs are language-focused models inside that category.
- GPT is one well-known family of large language models. ChatGPT is a conversational product built around GPT-style models, not a synonym for the whole generative AI category.
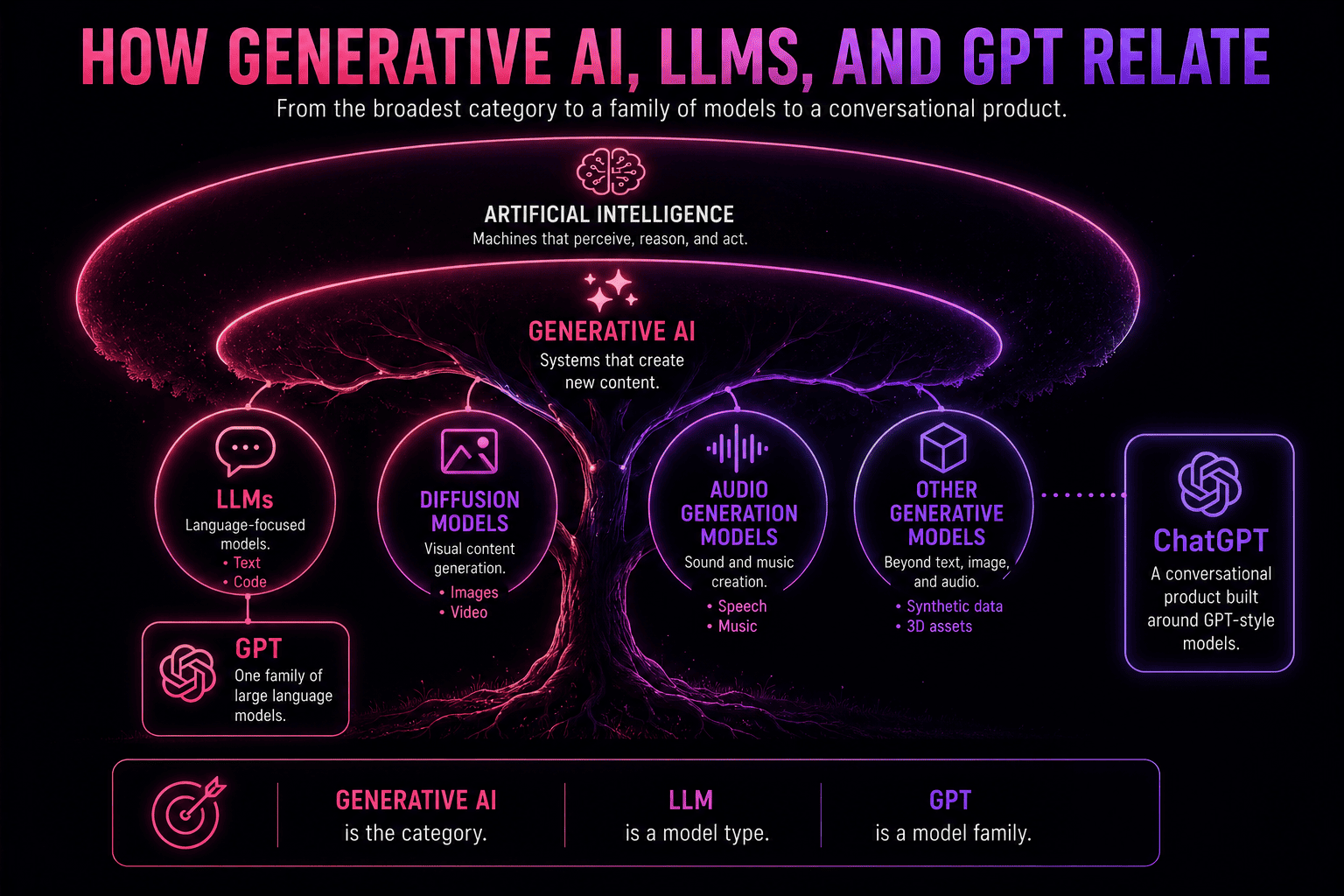
Here's the entire landscape:
| Term | What it means | Trained on | Typical outputs | Examples |
|---|---|---|---|---|
| Artificial intelligence | Systems that perceive, predict, reason, classify, or generate | Varies | Predictions, decisions, classifications, recommendations | Fraud detection, search ranking, automation |
| Generative AI | AI systems designed to create new content | Text, images, audio, video, code, structured data | Text, images, audio, video, code, synthetic data | DALL-E, Stable Diffusion, Sora, Gemini, ElevenLabs |
| LLM | A large language model trained to understand and generate human language | Mostly text and code | Text, code, summaries, answers, structured responses | Claude, Llama, Mistral, Gemini (language mode) |
| Multimodal models | Models that accept or produce more than one type of input/output | Natural language, documents, code, images (and sometimes audio/video) | Text, images, audio, or combinations | Gemini 1.5, Claude 3, GPT-4o |
In practice: use "generative AI" when you are talking about systems that create outputs across formats, including text, images, audio, video, code, or synthetic data. Use "LLM" when you are talking specifically about a language model trained to process and generate text or code. Use "GPT" only when you mean that specific model family or a product built around it.
Same Interface, Different Layers
But stacking these concepts into a table doesn't make the way they relate to each other self-evident, though. For example, most LLMs people interact with are generative AI systems — they generate text and code — but not every generative AI system is an LLM. A diffusion model creating images, a music generation model producing audio, or a generative adversarial network (GAN) producing synthetic visual data all fall under generative AI without being large language models.
The reverse confusion also shows up: some people use "generative AI" when they really mean "an LLM wired to a chat interface." That misnomer underexplains most of what a production AI application actually involves.
A comprehensive knowledge system like our platform, cognee, might hook onto an LLM for language while using a vector database for retrieval, a knowledge graph for mapping data points and their relationships, a workflow engine integration for actions, and act as a persistent memory layer for continuity across sessions. The LLM is just the part users notice — not the whole system.
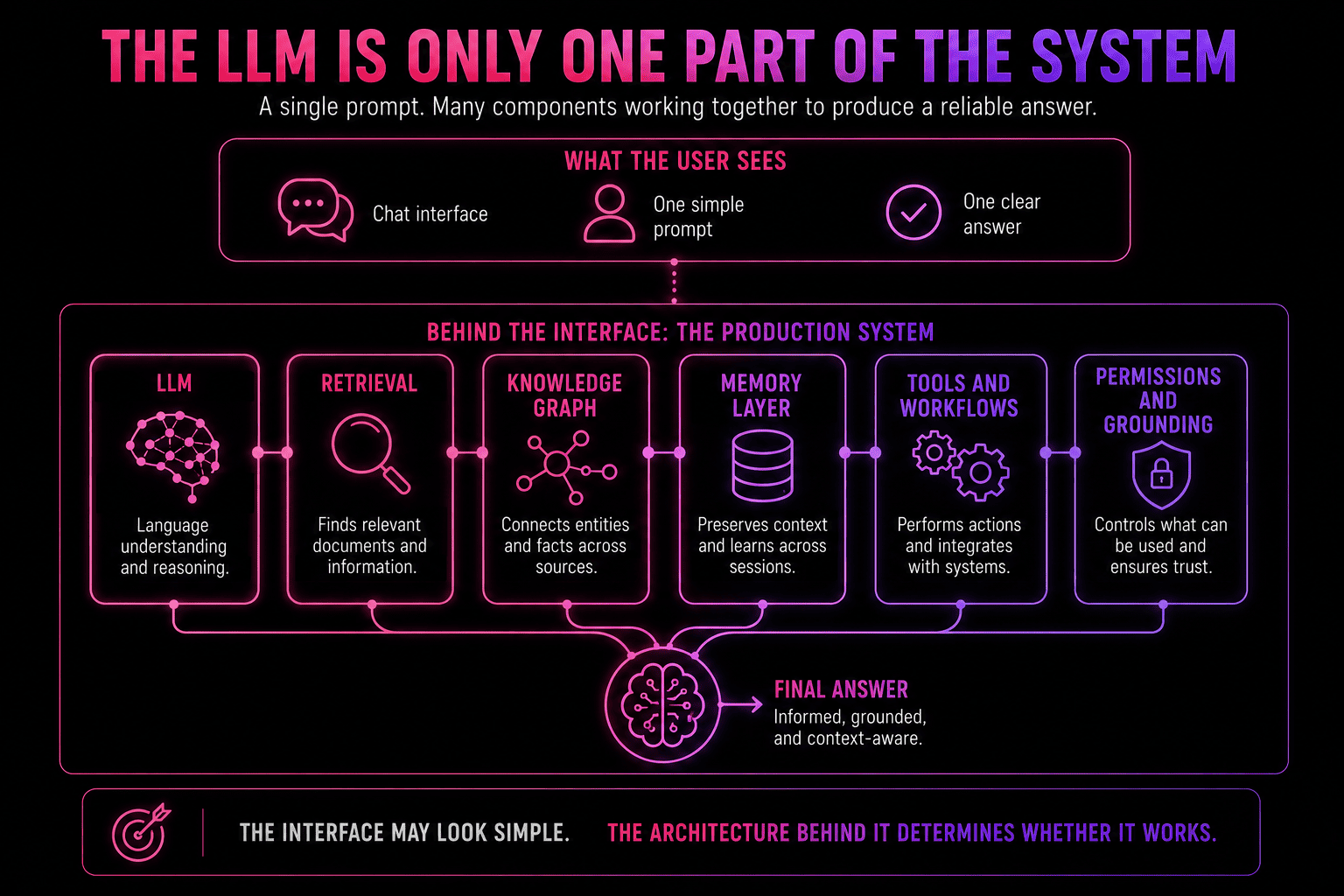
So, the model type explains what the system is built to do, but the architecture behind it is what determines whether it's actually useful.
The Output Makes the Difference
Now that we've covered the conceptual distinctions between the two, let's make this more practical.
Gen-AI
So, generative AI is any AI system that produces an output that didn't exist in that exact form before. Traditional machine learning is largely built to classify, rank, detect, or predict. Generative AI goes a step further — it creates.
The output might be text, images, audio, video, software code, design variations, simulations, synthetic datasets, or multimodal combinations of those. In every case, the defining act is original content generation, not classification or prediction.
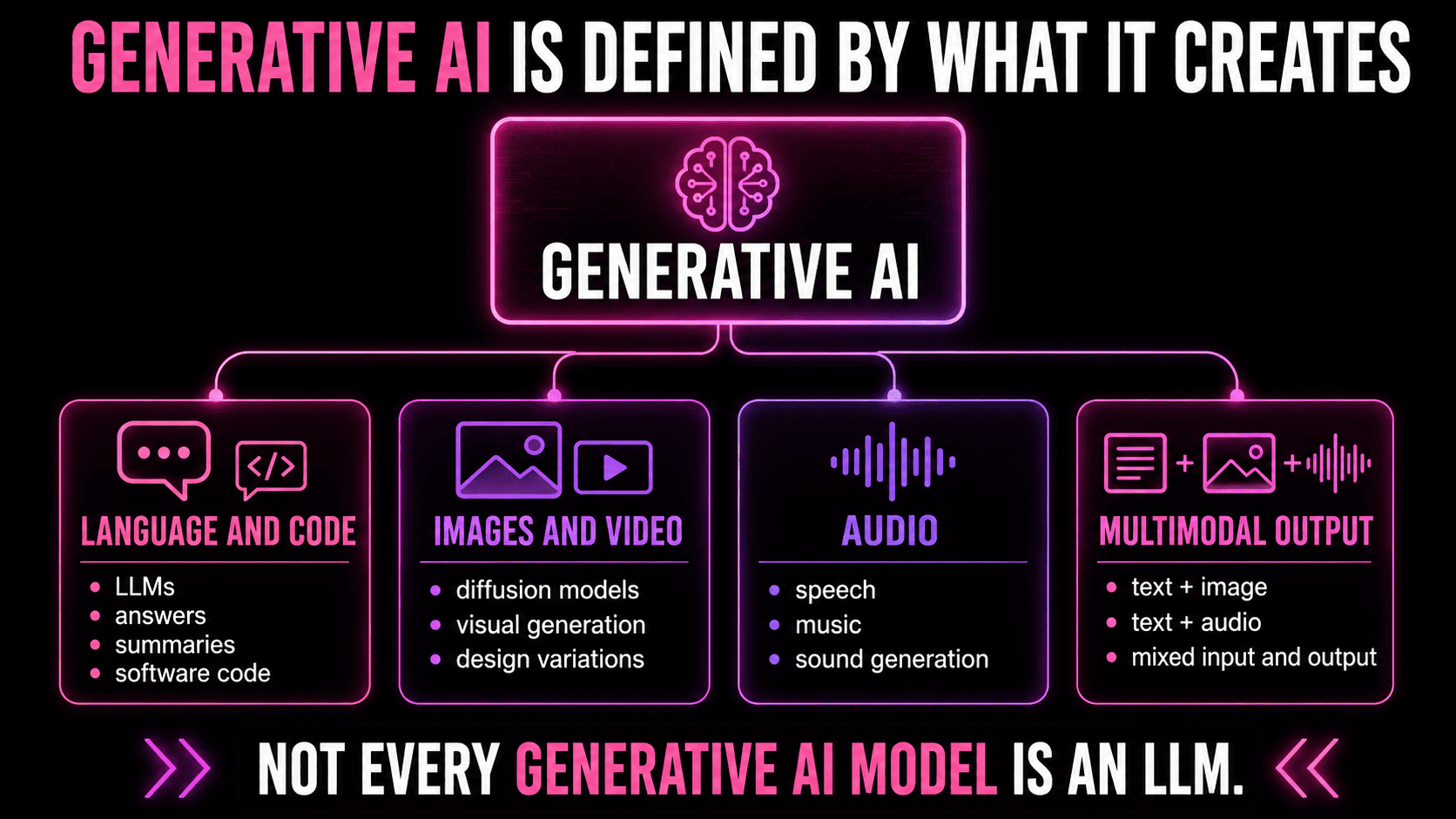
That's how "generative AI" became such a broad label — it accurately describes most general user-facing platforms like writing assistants, image models, music tools, coding assistants, and multimodal products.
But different gen-AI architectures are optimized for different kinds of output. Diffusion models are most commonly associated with image generation. GANs have been widely used for synthetic images and visual data. Multimodal models can work across input and output types — text, images, audio — within the same interface. LLMs handle language and code.
For this reason, "generative AI" isn't precise enough to describe a product architecture on its own. It tells you a system creates something, but not what kind of model is doing it, what it was trained on, how reliable the output is, or whether the result can be traced back to a source.
As a result, two products can both be described as generative AI while having almost nothing technically in common: one generates product images from a text prompt; another drafts contract summaries from uploaded PDFs.
LLMs
As for LLMs, they are, again, machine learning models trained to process and generate language. Text, code, instructions, documents, questions — these are their native inputs. Modern LLM-based systems increasingly accept images or structured data too, but their core operation still revolves around natural language.
The phrase "large language model" tells you three things:
-
Large. These models are trained on massive amounts of data and contain billions of parameters. That scale is part of what lets LLMs recognize patterns across grammar, style, reasoning structures, domain-specific terminology, and software syntax all at once.
-
Language. LLMs interpret, transform, and generate human language. While earlier natural language processing systems were built specifically for tasks like sentiment analysis, translation, and entity recognition, today's LLMs can summarize, classify, translate, answer questions, write code, restructure information, and follow multi-step instructions through a single prompt.
-
Model. An LLM is not a complete application, it's a component.
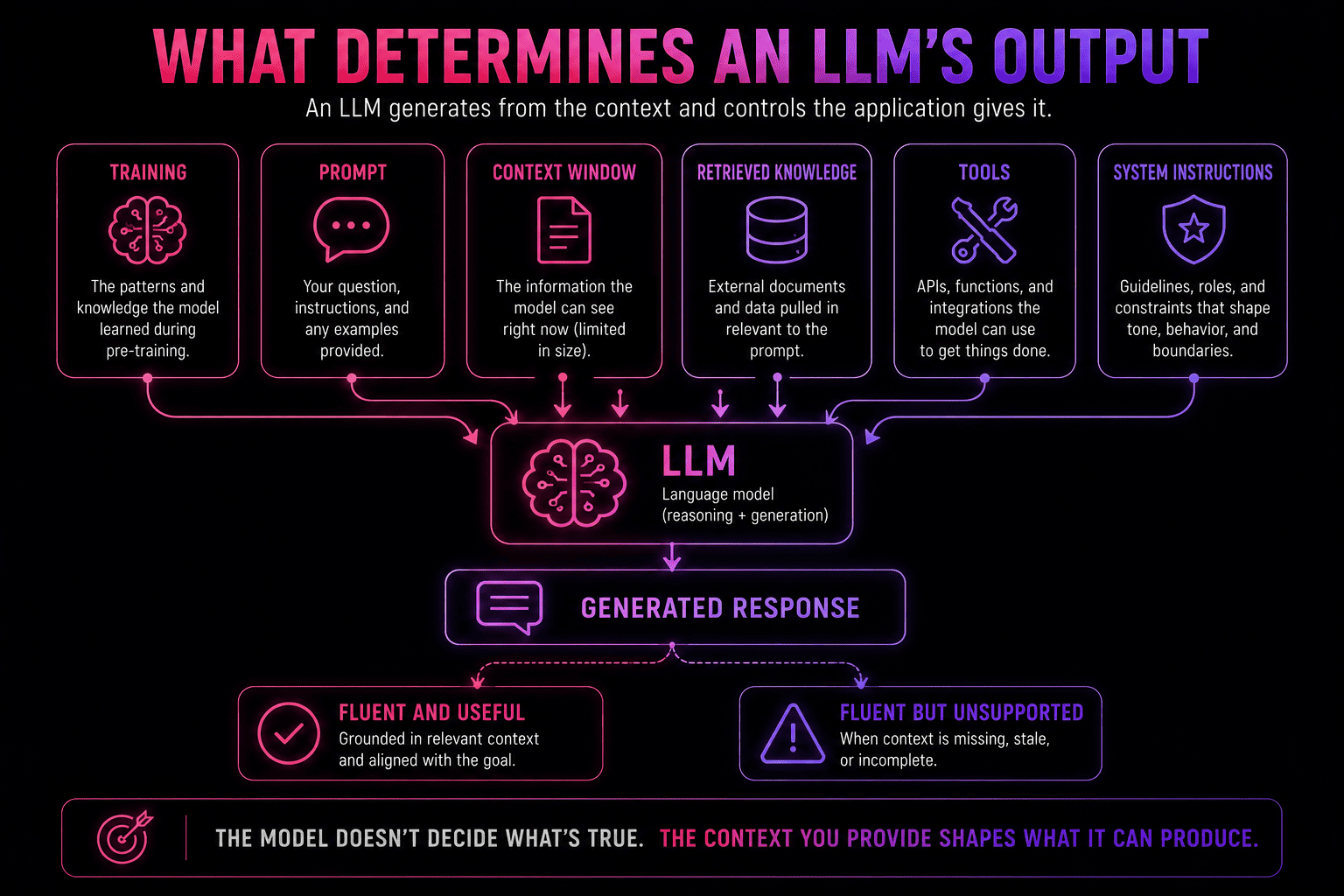
Its performance depends on its training, the prompt it receives, the context window it's given, any retrieved information, tool access, system instructions, and the product design wrapped around it.
LLMs are built on neural networks and trained to predict language patterns by learning how words, tokens, code fragments, concepts, and structures tend to relate to each other. When prompted, they generate a response by producing likely continuations that fit the instruction and available context. Their outputs, even the complex ones, are language-based: answers, summaries, rewrites, code, tables, classifications, JSONs, how-to's, etc.
The LLM mechanism is powerful precisely because so much real work is done through language. Documentation, tickets, emails, contracts, product specs, code comments, research notes, meeting transcripts, customer conversations — LLMs make all that material queryable, summarizable, and actionable at a scale that wasn't previously possible.
But their strength is also where their architectural limits start to show. An LLM will blend training data, retrieved snippets, and prompt instructions to produce coherent language even without factual grounding. Fine for a simple chat, but use it for anything involving enterprise knowledge, customer data, or consequential decisions and you got yourself a problem.
So, an LLM can turn context into language, but the question is whether the right context ever reaches it in the first place.
Fluency Isn't Knowledge
Generative AI systems can produce high-quality outputs, but, as we've all experienced by now, the ability to generate a response to almost any prompt doesn't mean the response is correct. A coherent-sounding answer can be entirely wrong; a summary that reads smoothly can be missing the one sentence that mattered; a realistic-looking image can contain physically impossible details.
For LLMs specifically, this problem has a name: hallucination. The model produces fluent, confident language even when the underlying source material is missing or incomplete. It knows what a "good" answer looks like, and will generate one regardless of whether it actually has the right information.
This is where most AI projects hit a brick wall. The first demo works because writing out a paragraph or answering a general question is a broad and forgiving task. But when the system gets asked to do real work, like handling private data, conflicting documents, multiple versions of the same policy, and/or customer-specific context, the model's access to context becomes the bottleneck.
Even a model trained on vast amounts of data doesn't have an organization's living knowledge. It may not include the latest documentation or know which source is authoritative when two documents conflict, or which policy replaced another, or which facts are safe to surface for one user but not another. It won't remember what happened in a previous session unless the application explicitly gives it that memory.
Why RAG Became (and Stopped Being) the Standard
All this is what made retrieval-augmented generation — RAG — such a central pattern in LLM application design. Instead of asking a model to answer from training alone, the system retrieves relevant information from external sources and passes that context to the model before generation. For many tasks, it's a solid foundation and a meaningful upgrade over a raw model call.
But basic retrieval has hard limits. Searching for semantically similar text chunks can indeed surface related content, but real knowledge is in more than conceptual associations — it's in understanding how the information is connected.
A retrieval system that finds nearby text can miss the structure of the data it's looking at, like overlooking the relationship between a policy update and the product line it governs. Grounding AI memory in ontologies and knowledge graphs is one approach to solving this.
Better context means the model understands how the pieces fit together, i.e. which source is newer, which person made which decision, which document superseded another. The better the surrounding architecture answers those questions, the more useful the LLM becomes.
The Memory Layer Most LLMs Are Missing
cognee is designed to solve this architecture problem. It's not a replacement for the LLM — it just feeds it better material by turning unstructured data into structured memory that AI agents and LLM workflows can use to retrieve relevant context, follow relationships, and ground responses in information that belongs to the user or organization.
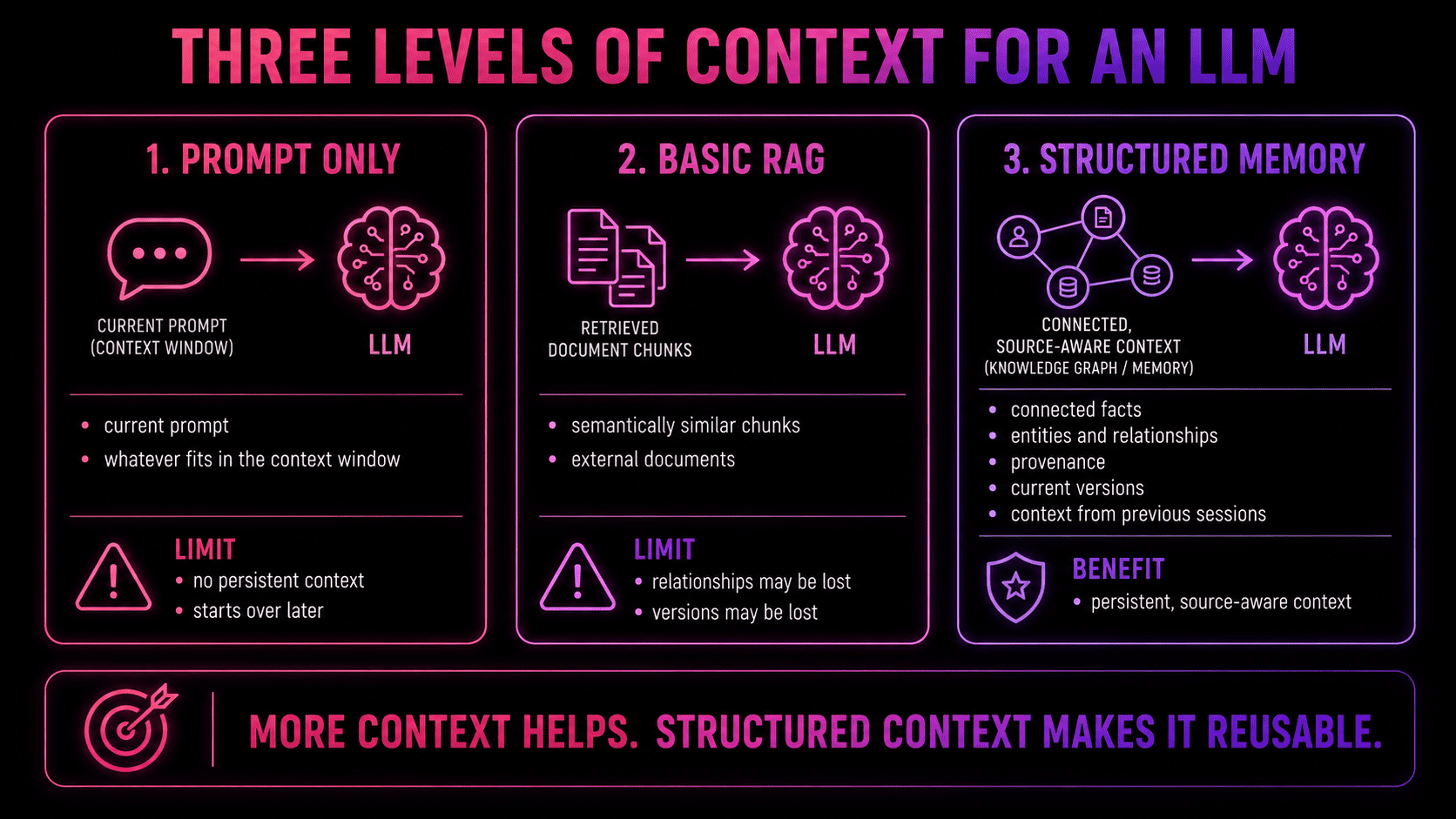
This enables the LLM to move from prompt-only generation to context-aware generation:
- In a prompt-only setup, the model sees what fits in the current context window.
- In a basic RAG setup, it gets semantically similar snippets — useful but hollow.
- With a memory layer like cognee, the system can preserve information across sessions, connect facts and entities, and retrieve context with a stronger understanding of how the knowledge is structured.
The same distinction plays out at the AI agent memory level:
- A stateless agent rediscovers the same context on every run.
- An agent with unstructured memory generates noise.
- An agent with proper long term memory for AI knows what to keep, what to connect, and what to surface when it matters.
A quick example: How this works in customer service
On the surface, a customer service assistant looks simple — a customer asks, the assistant answers. The LLM handles the language: interpreting the question, deciding what kind of answer is needed, writing a natural response. But the correct answer to a question about a refund policy, a warranty condition, or a billing issue can't come from general training data. It has to come from the company's actual knowledge — the knowledge base, support notes, product documentation, previous tickets, account details.
A basic RAG implementation gets you part of the way there. But customer support knowledge isn't a one-dimensional set of pages. One answer can depend on the relationship between a customer, a product version, a service plan, a previous ticket, and a policy updated last month.
A production architecture for this use case usually separates memory by scope: organization-level for product policies, agent-level for task patterns, user-level for customer history. Our post on how cognee can be employed to support AI agents walks through exactly this implementation pattern.
The model generates. The memory layer gives it something specific, current, and connected to generate from.
If you're building a system that depends on what the model knows — not just what it can write…
Try cognee right now with Cloud deployment (serverless or private infrastructure) or book a call to discuss on-prem solutions for enterprise use cases.
FAQ
Does a bigger model solve the knowledge problem?
No. Scale doesn't fix a retrieval or context problem. If the system retrieves the wrong document, lacks current information, or can't trace answers to sources, a bigger model just produces more polished wrong answers. What matters is whether the model has access to the right context, whether that context is well-structured, and whether outputs can be verified against reliable sources.
Can an LLM be useful without RAG or memory?
Yes, for general writing, summarization, brainstorming, classification, translation, and other tasks where the needed context is already in the prompt or does not depend on private, current, or changing information. But for enterprise knowledge, customer support, research, and agentic workflows, the model usually needs retrieval, memory, source grounding, or tool access to produce reliable answers.
Is RAG enough for a production system?
It's often a strong starting point, but not always sufficient. RAG helps an LLM answer from external documents rather than training data alone — but basic retrieval still misses source hierarchy, document freshness, entity relationships, and long-term context across sessions. Many production systems move toward richer memory architectures for exactly this reason. Here's a concrete look at how structured memory can be added to an agentic workflow without restructuring your stack.


